




本記事の日本語翻訳版はこちらに掲載しています。
■AIのリスクベーステスト/Risk-Based Testing for AI (日本語翻訳版)
This article was written by Dr. Stuart Reid in commemoration of his upcoming presentation at the Premium Seminar to be held on September 26, 2023 (Tuesday).
Please refer to the following link for more details about the Premium Seminar:
■9.26開催!Stuart Reid博士 特別セミナー|知識ゼロから学ぶAIテスト

Introduction
Risk-based testing (RBT) has been around in various forms since the early 1990s and accepted as a mainstream approach for the last 25 years. It is the basis for the ISO/IEC/IEEE 29119 series of software testing standards, which mandate that all testing should be risk-based. RBT is also an integral part of tester certification schemes, such as ISTQB, which means that globally well over a million testers have been taught the RBT approach.
AI has been around even longer than RBT, however it is only in the last few years that it has become a mainstream technology, which many of us now rely on. This evolution from the lab to its day-to-day use, sometimes in critical areas, has meant that there is now an increasing acceptance that commercial AI systems need to be systematically tested. The widespread lack of public trust in AI systems reinforces the need for a more professional approach to the testing of these systems.
According to some data scientists, AI is so different from traditional software that new approaches to developing these systems are needed, including how they are tested, and by whom. This article introduces the basic concepts of RBT, demonstrates its adaptable nature, and shows how it can, and should, be used for the testing of machine-learning systems (MLS).
This article lists many of the risks that are unique to MLS, and, through these, identifies several new test types and techniques that are needed to address these risks. This article concludes by explaining the need for specialist testers who understand not only these new test types and techniques, but also the AI technology that forms the basis of these systems.
Risk and IT Systems
We all use risk on a day-to-day basis in our daily lives (e.g. ‘should I walk the extra 50 metres to the pedestrian crossing or save time and cross here?’) and similarly many businesses are based on the management of risk, perhaps most obviously those working in finance and insurance.
For those who work in the development and testing of IT systems, the use of a risk-based approach has long been accepted as a means of ensuring trust in such systems. Many sector-specific standards, some of which date back nearly 40 years, exist for both safety-related and business-critical areas, and define requirements based on risk for both software development and testing.
Why Risk-Based Testing?
Risk-based testing provides several benefits, such as:
More Efficient Testing If we use risk-based testing, we identify those parts of the system under test that are higher risk and we then spend a higher proportion of our test effort on those parts. Similarly, we spend less of our test effort in the areas that are lower risk. This typically results in a more efficient use of testing resources – with fewer high-scoring risks becoming issues after the system is delivered. This aspect of RBT can simply take the form of adjusting the amount of test effort used, but it can also include the use of specialist types of testing to address specific risk areas (e.g. if we have a user interface risk, we may decide to perform specialist usability testing to address the risk).
Test Prioritization If we know which of our tests are associated with the highest risks, then we can schedule those tests to run earlier. This has two main benefits. First, if our testing is ever cut short, we know we have already addressed the highest risk areas. Second, it means that when we do find a problem in a high-risk area, then we have more time left to address it.
Risk-Based Reporting and Release By using a risk-based approach, then at any time, we can easily report on the current state of the system in terms of the outstanding risks (i.e. those risks that have not been tested and treated). This allows us to advise the project manager and customer that if they decide to release the system now, then all the risks we have not yet tested still exist (and so they are accepting the system with those risks). Thus, any decision they make to release the system can be based on risks that they know about and have agreed exist.
The RBT Process
Risk-based testing follows a typical risk management process, a simplified version of which is shown in Figure 1.
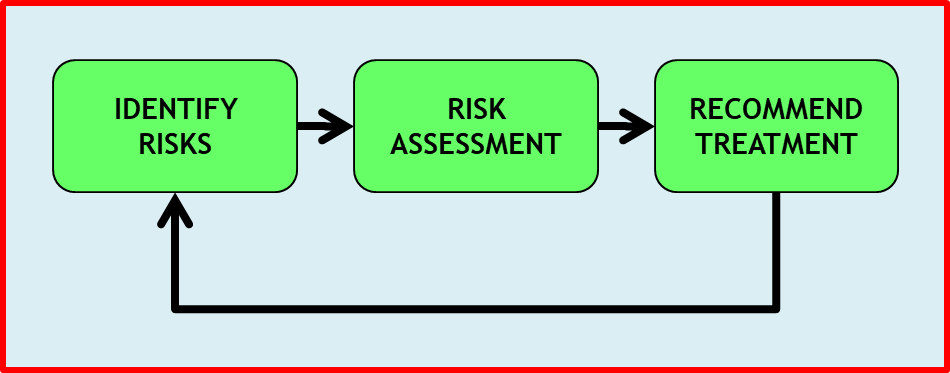
First, we identify any applicable risks. Next, we assess these risks so that we can estimate their relative importance. And then we decide which of the risks can be handled by testing. Risk management is hardly ever a one-off, however, and normally it is an ongoing process that handles changing risks.
Risk Identification
RBT is concerned with the identification and management of two types of risks: project and product risks.
Project risks are the same type of risks as used by project managers (often documented in a Project Risk Register). They are largely concerned with whether we will deliver on time and within budget. Project risks also cover the availability of suitably-skilled testers and the likelihood of code being delivered to the testers from the developers on time. As a test manager, the project risks can have a huge influence on the type and amount of testing we include in the test plan. For instance, using a new test technique may introduce the risk of a lack of required implementation skills in the test team and a risk of increased test tool costs.
Product risks are more specific to testing. These are risks associated with the deliverable product and so these are the risks that tend to affect the end users. At a high level, we may consider product risks in terms of functional and non-functional quality attributes. For instance, a functional product risk may be that the software controlling the car window fails to respond appropriately when the closing window encounters a child’s head. Non-functional product risks could be that the user interface for the in-vehicle infotainment system is difficult to read in bright sunlight (perhaps due to poorly-managed contrast and brightness), or that the response times when a driver selects a new function are too slow.
When attempting to identify risks, we ideally need to involve a wide variety of stakeholders. This is because different stakeholders know about different risks and we want to find as many potential risks as possible (if we miss an important risk, it is highly-likely that we will fail to test the corresponding part of the system in sufficient depth, so increasing the likelihood of missed defects in that area).
The requirements should always be considered as an important source of product risks. Not delivering requested functionality is an obvious risk and one that the customer is unlikely to consider acceptable (so increasing the impact of this type of risk).
SIDEBAR: Why Not Requirements-Based Testing? In the past, testing followed a requirements-based approach, where the testing simply covered those elements explicitly requested by the customer. But what happens in the typical situation when the customer doesn’t state their requirements perfectly? For instance, if they do not document all their required features, or they do not specify all the relevant quality attributes, such as response times, security requirements and the level of usability they needed. The simple answer is that requirements-based testing does not cover these missing requirements – and so only provides partial test coverage of the system that the customer wants. And what happens when the customer’s requirements aren’t all equally important (the normal state of affairs)? With requirements-based testing, every requirement is treated the same – so our autonomous car would have its pedestrian avoidance subsystem tested to the same rigour as the in-vehicle infotainment (IVI) system. Luckily, for safety-related systems we don’t use requirements-based testing alone – the sector-specific standards for such systems tell us that we must employ a risk-based approach with integrity levels. However, with any system, if we treat all the requirements as equally important, this will lead to inefficient use of the available testing resources. So, if requirements-based testing is inefficient and leads to poor test coverage, then what is the alternative? Risk-based testing accepts that unstated requirements exist for all systems, and so missing requirements are treated as a known risk that needs to be handled. When missing or poor requirements are perceived to be a high-enough risk, then the tester will normally talk to users and the customer to elicit further details about their needs to treat this risk. Testers may also decide to use a specific test approach, such as exploratory testing, which is known to be effective when complete requirements are unavailable.
Risk Assessment
The score assigned to a risk is evaluated by considering a combination of the likelihood of the risk occurring and the impact of that risk if it becomes an issue. In an ideal world, we would be able to precisely measure the size of each risk. For instance, if the likelihood of a risk occurring was 50% and the potential loss was $100,000, we would assess that risk at $50,000 (risk score is normally calculated as the product of impact and probability). In practice, it isn’t so simple.
We are rarely able to get the business to accurately tell us what the impact would be if a particular risk became an issue. Take, for example, risks associated with the user interface of an in-vehicle infotainment system. We may know from feedback on the previous version, that car drivers found the user interface difficult to use, and so we have identified this as a risk with the new interface. But what is the business impact? This can be extremely difficult to measure, even in retrospect, but predicting it before a vehicle even goes to market is practically impossible.
Calculating the probability of a risk becoming an issue is often considered an easier task, as we normally get the information needed to determine this from the developers and architects (who we, as testers, are normally closer to), and perhaps from historical defect data. However, estimating the likelihood of a failure in a specific area is not an exact science. We may talk to the architects and get their opinion on whether the part of the system associated with the risk is complex, or not. We may talk to the developers and ask how they rate the likelihood of failure, which may depend on whether they are using unfamiliar development techniques or programming languages, and we could also estimate the capabilities of the architects and developers. However, we are never going to be able to come up with a precise probability for a software part of the system failing (hardware is easier to predict).
So, if we cannot accurately assess risk score when performing RBT, what do we do? First, we don’t measure risk absolutely. Instead, we assess risks relative to each other, with the aim of determining which risks we need to test more rigorously and which risks we need to test less rigorously. We make informed guesses. This sounds unscientific, but, in practice, the differences between risk scores are normally so large that our informed guesses are good enough.
The most common approach to risk assessment for RBT is to use high, medium and low (for impact, likelihood and the resultant risk score). Figure 2 shows how this can work. The business provides a low, medium or high impact for a given risk, while the developers provide a low, medium or high probability of failure. These are combined, as shown, and the resultant position on the graph gives us the relative risk score. It is important to emphasize that if actual numbers are assigned as risk scores (rather than simply reading off a ‘high’, ‘medium’ or ‘low’ risk score from the position on the graph) then these numbers are only useful for determining the relative exposure for different risks – the actual scores should not be used to directly determine how much testing to perform. For instance, if we had two risks, one ‘Low-Low’ with a nominal score of 1, and one ‘High-High’ with a nominal score of 9, we do not assign nine times as much effort to the second risk than the first risk. The scores, instead, should tell us that the second risk is relatively higher than the first risk, and so we should assign more testing to it. If you need to convince yourself that this is correct, you might like to try applying similar approaches to the same two risks but using different scales for impact and likelihood (e.g. 1 to 3 and 1 to 5) – you will soon see that the result can only be useful as a relative risk score.
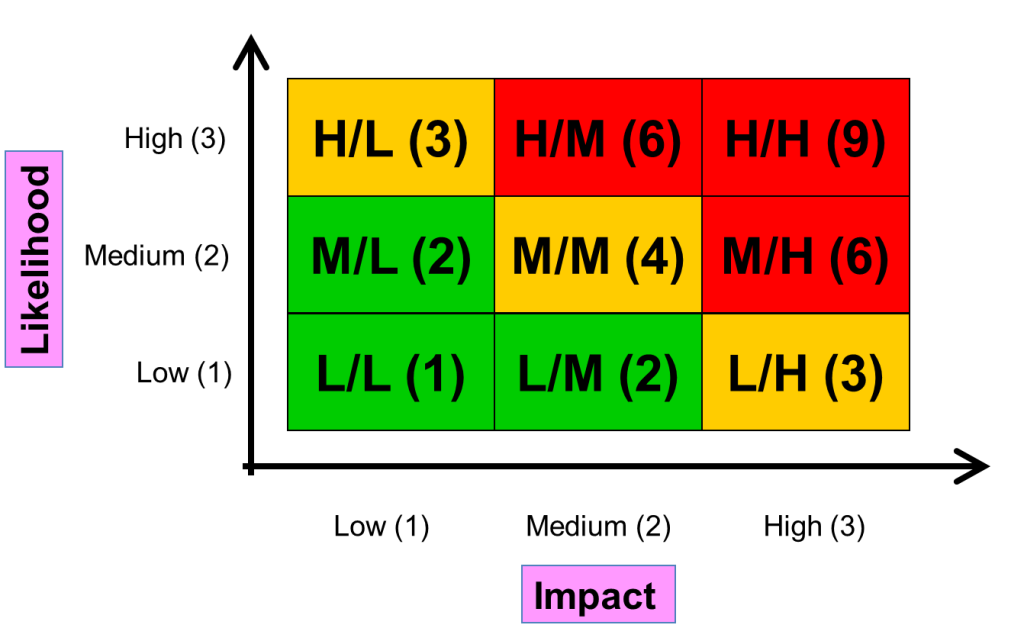
So far, so simple. Here are some suggestions for when you use this approach. Make sure that the stakeholders who give you the scores for likelihood and impact use the full range (from low to high). You will find that some stakeholders (especially users) think that ‘their’ part of the system is the most important part and so always score every risk in their area as high impact. This is not especially useful, as we are trying to get relative scores, so that we can discriminate between risks, and if most risks are scored high then we cannot discriminate between them.
Also, ensure the stakeholders approve the risk scores. It can be extremely frustrating when a bug is found post-release when the customer complains that you should have found this bug because it was in a ‘high risk’ area. However, you can clearly recollect that they agreed to consider that area as low risk, resulting in comparatively less testing than performed in some of the other areas.
Finally, there is a third parameter that we often use in our calculation of the risk scores. This is the frequency of use. Imagine we are performing a risk assessment and two system features are both assigned as high risk, but we know that the first feature is only used once per day, while the second feature is used every minute. This extra information should tell us that the second feature warrants a higher risk score, as if that feature fails, the potential cost of failure will be far higher.
Risk Treatment
The third step of the RBT process is risk treatment. At this point we typically have several options. For instance, we may decide that for a given, low-score, risk then the cost of testing is too high when compared with the cost of the risk becoming an issue. This is often the case for low-scoring risks – and it is quite common to set a threshold risk score, and not test risks that fall below this level. Sometimes we might find that the testing costs for a given risk are very high (e.g. when we need specialist testers and tools) and may decide that it is not cost-effective to test that risk even when the risk score is relatively high. In such cases, we normally try and treat the risk another way, and we may ask the developers to try and reduce the risk, for instance, by introducing redundancy to handle a failure, or we may recommend that the users live without that feature in the system.
When we treat risks by testing, we are using testing to reduce the associated risk score. The score is reduced by decreasing the perceived probability of failure – if a test passes, then we conclude that the probability of failure is reduced (the impact typically stays the same). We cannot normally get rid of a risk completely in this way as testing cannot guarantee that the probability of failure is zero (we can never guarantee that no defects remain). However, if we test a feature and the test passes, we now know that for that set of test inputs in that test environment, the feature worked, and the risk did not become an issue. This should raise our confidence about this feature, and if we were to re-assess the risk we would assign it a lower probability of failure. This decrease may be enough to move the risk score below the threshold under which we have decided that testing is not worthwhile, otherwise we run more tests until our confidence is high enough (and our perceived probability of failure is low enough) to get the risk score below the threshold.
Risk treatment by testing can take several forms and is based on both the risk type and the risk score. At a high level, we often treat risks by deciding what is included in the test strategy. For instance, we may decide which test levels to use on the project (e.g. if integration is considered high risk, we perform integration testing), and we may decide which test types to use for different parts of the system (e.g. if we have high-scoring risks associated with the user interface, then we are more likely to include usability testing as part of our test strategy). Risks can also be used to decide which test techniques and test completion criteria are selected, and the choice of test tools and test environments can also be influenced by the assessed risks.
At a lower level, we may decide (as individual testers) how we will distribute our tests across a single feature based both on the assessed risks and our knowledge of the system and its users. For instance, if we are testing a feature and we know that certain parts of it are used more often than others, it would be reasonable to spend more time testing the more frequently-used parts (all else being equal).
Good risk treatment is highly-dependent on the skills and experience of the tester (and test manager). If we only know two test techniques then we have four possible options (use technique A, use technique B, use both techniques, or use neither). However, if neither of the techniques we know is suitable for treating the perceived risk, then the effectiveness of our risk-based testing is going to be severely-limited. On the other hand, if we have knowledge of a wide range of testing types and techniques, we are far more likely to be able to choose an appropriate treatment.
RBT should NOT be a One-Off Activity
On many projects, risk-based testing is performed as a limited one-off activity, used only at the start of a project to create the test plan and its associated test strategy, after which nothing changes. But, as is shown by the arrow returning to ‘identify risks’ in the simplified risk management process in Figure 1, RBT should continue as an ongoing set of activities, ideally until the system is retired.
As was mentioned previously, as soon as our tests start passing, our confidence increases, and the perceived probability of failure should decrease. Thus, as we run tests, the risk levels change, and so our testing should also change to reflect this. However, it also works the other way – when our tests fail. In this case the probability of failure (for these test inputs) is now 100% and we no longer have a risk, instead we have an issue that must be handled (risks have a probability of failure that is less than 100%, otherwise they are an issue).
One of the principles of testing is that defects cluster together, so when we find a defect, we should immediately consider the likelihood that we have just discovered part of a defect cluster. Thus, the parts of the system near our newly-found defect will now have an increased likelihood of failure. This will increase the associated risk score – and this should mean that more testing in this area is considered.
Risks do not only change because of the testing. Customers often change their requirements mid-project, which immediately changes the risk landscape. Also, external factors, such as the release of competing systems may change the business impact of certain risks (perhaps unique features are now more important) or it may be that the imminent release of a competing system means that delivery (and testing times) are shortened to allow release before the other system, so increasing project risks. Similarly, an unexpected winter ‘flu epidemic could also change project risks associated with the availability of testers and the associated capabilities in testing they provide.
RBT and AI Systems
So, does anything change when we test AI systems? In short, the answer is ‘No’. When testing, RBT can, and should, be applied to all systems, whether they contain AI components or not. However, the testing of AI systems is different than for traditional, non-AI systems – and that is because the risks are different.
There are many types of AI systems (e.g. machine-learning systems (MLS), logic- and knowledge-based systems, and systems based on statistical approaches), and each will have its own specific risks, so each type of AI system is tested differently. At present, machine-learning systems are the most popular form of AI, and so we will next look at how we test MLS using RBT.
続きを読むにはログインが必要です。
ご利用は無料ですので、ぜひご登録ください。








