はじめまして、QAエンジニアのT.Tです。
AIの世界では、ChatGPTをはじめとする生成系AIが広がり、テキスト生成モデルである大規模言語モデル(LLM)の仕事での利用も増えています。
今回紹介するオープンモデルLLMは、AI技術の発展において重要な役割を果たしています。ChatGPTのようなクローズドなLLMモデルは高性能ですが、LLMを活用したツール作成や検証などの研究目的での利用にはコスト面の課題があります。オープンモデルLLMは 無料で利用できるため、スタートアップや予算の限られたプロジェクトなどでも、柔軟に対応できる点が評価されています。また、Google Colabを使えば高性能な環境を用意せずにオープンモデルLLMを試せます。
この記事では、GPT-3やGPT-4に比べてコンパクトながら高性能な、GoogleのオープンモデルLLM「Gemma」をGoogle Colabで使用する方法を解説します。
オープンモデルLLM「Gemma」とは
Gemmaの概要
Gemmaは、Googleが開発した軽量で最先端のオープン型大規模言語モデル(LLM)です。Google DeepMindとGoogleの他のチームによって開発され、ラテン語で「宝石」を意味する名前が付けられています。また、Googleは2024年6月に「Gemma」の新バージョンGemma 2をリリースしました。
特徴とメリット
- オープンモデル: Gemmaは誰でも自由にダウンロードして利用できるオープンモデルです。
- 軽量: 「Gemma2 2B」「Gemma2 9B」「Gemma2 27B」の3つのサイズがあり、なかでも「Gemma2 2B」は軽量でありながら高性能を実現しており、モバイルデバイスや組み込みシステムでの活用が期待できます。
- 商用利用可能: 利用規約に同意すれば、Apache License 2.0のもとで商用利用が可能です。
- コスト効率: 無料で利用できるため、スタートアップや予算の限られた組織にとってアクセスしやすいです。
- 幅広い利用可能性: Google Colabなど、さまざまな環境で実行可能で、手軽に利用できる環境が整っています。
- 安全性: 学習データから特定の個人情報や機密データを除外しており、安全性が高いです。
- 高いパフォーマンス: 主要なベンチマークで高い性能を発揮しています。
Google Colab環境の準備
それでは、Gemmaを動かす環境であるGoogle Colabについて説明します。
Google Colabについて
Colab(正式名称「Colaboratory」)では、ブラウザ上で Python を記述・実行できます。Colab には、AIなど重い処理を高速に実行できるGPUが使用でき、しかも無料で使えます。特徴としては、以下の点があります。
- 環境構築がほぼ不要
- 簡単に操作が可能
- 無料でGPUが使用できる
- 共有が簡単にできる
注意点
便利なGoogle Colabですが、無料プランは次のような制限があります。
- 90分何も操作しないとリセットされる
- インスタンス起動してから12時間経つとリセットされる
- GPUを使いすぎると、しばらくGPUを使えなくなる(CPUは使用可能)
有料プランにすることで、上記を制限なく使うことができます。また、より速いGPUが使えたり、より多くのメモリを使えたりするメリットもあります。無料プランで物足りない場合は、検討してみても良いでしょう。また、Google Colabを使用するにあたり、APIキーやパスワードのような機密情報を扱う際には、コードに直接埋め込むことは推奨されません。秘匿情報を安全に扱うために「シークレット機能」を使いましょう。具体的な使い方は、後ほど説明します。
事前準備
早速、Google Colab を使っていきましょう。まずは、Gemmaを動かすための新規のノートブック(作業する場所)を作成するところから解説します。
- Google アカウントにログインした上で、以下の公式サイトにアクセスしてください。 https://colab.google/
- [New Notebook]をクリックして、新規のノートブック(作業する場所)を作成します。
![[New Notebook]をクリックして、新規のノートブック(作業する場所)を作成します。](https://sqripts.com/wp-content/uploads/2024/10/image-26.png)
すると、このような画面が表示されます。
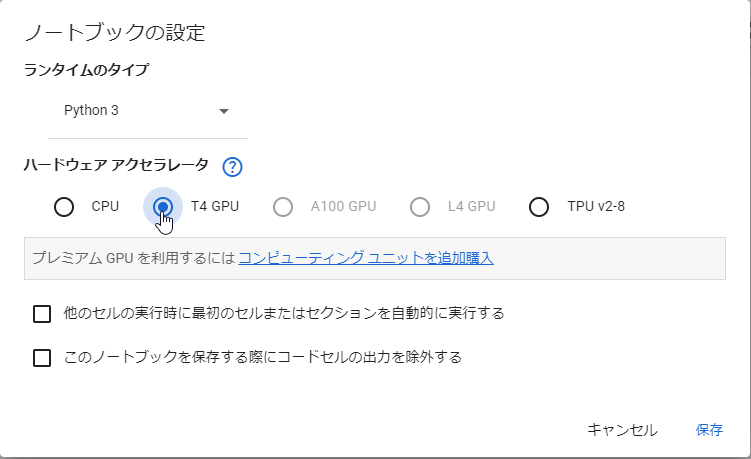
- 新規のノートブックの[編集]-[ノートブックの設定]を選択し、ハードウェア アクセラレータで、「T4 GPU」を選択します。「CPU」のままでGemmaを動かすと、処理スピードが非常に遅いので、必ず変更してください。
![[編集]-[ノートブックの設定]](https://sqripts.com/wp-content/uploads/2024/10/image-28.png)
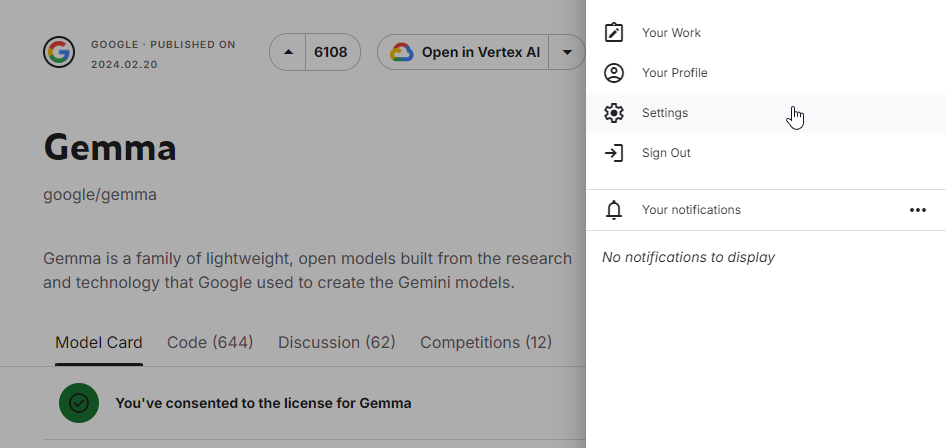
- Gemmaを利用するために、KaggleでAPI Tokenが必要です。まずは、以下のサイトにアクセスし、[Request Access]を押下して、Kaggleに登録して、Gemma利用規約に同意してください。 https://www.kaggle.com/models/google/gemma/
![[Request Access]を押下](https://sqripts.com/wp-content/uploads/2024/10/image-30.png)
以下のように表示されれば登録完了です。
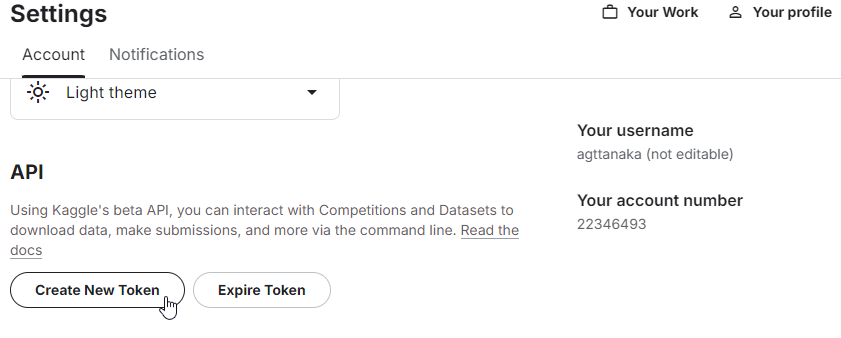
- 次に、API Tokenを生成します。アカウント設定ページにアクセスして、[API]のセクションで「Create New API Token」をクリックします。ダウンロードしたjsonファイルに、usernameとkey(API Token)が記載されています。これは、後ほど使用します。
これで事前準備は完了です。
Gemmaのセットアップ手順
それでは、早速Gemmaを動かしてみましょう。Gemma in PyTorch に記載されている情報を参考に、実行していきます。
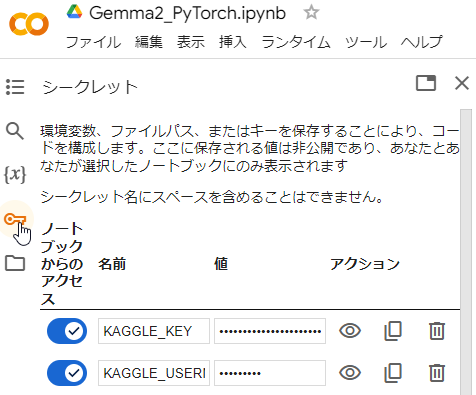
- まずは、先ほど入手したusernameとkey(API Token)を、「シークレット」に登録します。「新しいシークレットを追加」を押下して、KAGGLE_USERNAMEと、KAGGLE_KEYを追加、usernameとkey(API Token)をそれぞれの値の部分に入力します。
- 次にシークレットの情報をプログラムで読み込みます。
[+コード]を押下して、次のプログラムコードを入力します。全て入力が終わったら、「Shift + Enter」を押します。これにより、先ほど入力したセルのプログラムを実行して次のセルが選択されます。(以後、プログラムコードの実行は全て「Shift + Enter」で行います。)

import os
from google.colab import userdata # `userdata` is a Colab API.
os.environ["KAGGLE_USERNAME"] = userdata.get('KAGGLE_USERNAME')
os.environ["KAGGLE_KEY"] = userdata.get('KAGGLE_KEY')
これで、KAGGLE_USERNAMEとKAGGLE_KEYをプログラム中で使用できます。プログラム中に直接usernameとkey(API Token)を記載すると、セキュリティ的に良くないので、シークレット機能を活用してください。
- 次にGemmaを動かすのに必要な各種ライブラリをインストールします。
!pip install -q -U torch immutabledict sentencepiece
- モデルの重みをダウンロードします。
ここでは、Gemma2 2Bモデルの指示用調整(IT)「2b-it」を選択しています。9Bや27Bモデルは、無料のGoogle Colabでは、メモリの関係で動かせませんでした。
# Choose variant and machine type
VARIANT = '2b-it' #@param ['2b', '2b-it', '9b', '9b-it', '27b', '27b-it']
MACHINE_TYPE = 'cuda' #@param ['cuda', 'cpu']
CONFIG = VARIANT[:2]
if CONFIG == '2b':
CONFIG = '2b-v2'
import os
import kagglehub
# Load model weights
weights_dir = kagglehub.model_download(f'google/gemma-2/pyTorch/gemma-2-{VARIANT}')
# Ensure that the tokenizer is present
tokenizer_path = os.path.join(weights_dir, 'tokenizer.model')
assert os.path.isfile(tokenizer_path), 'Tokenizer not found!'
# Ensure that the checkpoint is present
ckpt_path = os.path.join(weights_dir, f'model.ckpt')
assert os.path.isfile(ckpt_path), 'PyTorch checkpoint not found!'
- モデル実装をダウンロードします
# NOTE: The "installation" is just cloning the repo.
!git clone <https://github.com/google/gemma_pytorch.git>
import sys
sys.path.append('gemma_pytorch')
from gemma.config import GemmaConfig, get_model_config
from gemma.model import GemmaForCausalLM
from gemma.tokenizer import Tokenizer
import contextlib
import os
import torch
- モデルをセットアップします
# Set up model config.
model_config = get_model_config(CONFIG)
model_config.tokenizer = tokenizer_path
model_config.quant = 'quant' in VARIANT
# Instantiate the model and load the weights.
torch.set_default_dtype(model_config.get_dtype())
device = torch.device(MACHINE_TYPE)
model = GemmaForCausalLM(model_config)
model.load_weights(ckpt_path)
model = model.to(device).eval()
サンプルテストの実行
具体的なプロンプト(LLMに対する命令)を入力し、その応答を確認してみましょう。Wikipediaの「人工知能」の冒頭の解説文章を要約させてみます。
※以下では、文章を途中省略していますが、実際に実行する際は、Wikipediaの文章を入力しています。
prompt = """
次の文章を100文字に要約してください。
人工知能(じんこうちのう、英: artificial intelligence)、AI(エーアイ)とは、「『計算(computation)』という概念と『コンピュータ(computer)』という道具を用いて『知能』を研究する計算機科学(computer science)の一分野」を指す語]。
(中略)
「われわれは少し先までしか分からないが、多くのやるべきことが残っているのは分かる」。
""".strip()
# Generate sample
model.generate(
prompt,
device=device,
output_len=4096,
)
要約結果は次のようになりました。
- Gemma2の出力
AIの発展が非常に急速な進歩を遂げている一方で、今後さらに発展する可能性は十分にあり、その将来の進化をどのように予測するのかについては、まだ明確な答えは見つかっていない。
<end_of_turn>
ChatGPT-4oとの比較
大規模な商用モデルであるChatGPT-4oと比較してみました。
- ChatGPT-4oの出力
人工知能(AI)は、計算機を用いて知能を研究する計算機科学の分野であり、言語理解や推論などをコンピュータで実行させる技術である。AIは歴史的に大きく発展してきたが、未来に向けてさらなる課題が残っている。Gemma2とChatGPT-4oの出力結果を比較すると、どちらも要約の質は非常に高く、甲乙つけがたいと言えます。どちらも程よくまとまっており、ユーザーにとって有益な情報を提供しています。ただし、処理速度に関してはChatGPT-4oが圧倒的に優れており、これは使用しているマシンスペックの違いによるものと思われます。どちらのモデルもそれぞれの強みを持っており、用途に応じて使い分けることで、より効果的にAIを活用することができます。
- Colab上のGemma2:3分
- ChatGPT-4o:5秒
実務に利用できるか
さて、簡単に動かすことができたGemmaですが、実務に使えるかどうか、考えてみましょう。オープンモデルLLMであることから、次のようなシチュエーションで有益ではないでしょうか?
- 運用におけるコスト削減したい、低コストで試験的に導入したい
- セキュリティが厳しい環境でも社内データをLLMで活用したい
- 特定ドメインにおける自動化、効率化を図ったり、社内サーバーで安定して運用したい
- 社内のドキュメントを簡単に要約したい
ただ、課題がないわけではありません。
- パフォーマンス
商用のLLMに比べ、OSSモデルのパフォーマンスはやや劣る場合が多いです。特に、生成タスク(クリエイティブな文章作成やコード生成など)では、商用モデルの方がより洗練された結果となります。 - スケーラビリティ
大規模なOSS LLMを実務環境に導入するには、計算リソースが必要となり、その運用コストがかさむ場合があります。また、OSS LLMのモデルは商用モデルと比べて最適化されていないことが多く、パフォーマンスのチューニングが必要となってきます。 - 特定分野への適用
OSSモデルは一般的なデータで訓練されていることが多く、特定の業務ドメイン(例えば法務や医療)に対する特化はされていません。そのため、専門的なドメインに適応させるには追加のデータセットとトレーニングが必要です。一方、クローズドなモデルでは、特定のドメインに対応するよう事前に最適化されている場合が多く、専用のトレーニングデータやパラメータ調整が行われているため、特定分野への迅速な適応が可能です。これにより、企業や専門機関は必要なセキュリティやプライバシー保護を維持しつつ、高精度なモデルを利用できるメリットがあります。
まとめ
本ブログでは、Google Colabを利用してGemmaを実行することで、誰でも簡単に高度なAI技術を試すことができることが、確認できました。Gemmaに加え、Llama3やBLOOMなど多くのオープンソースLLMが存在し、それぞれの特徴と強みを活かして、AI活用の幅広い選択肢が提供されています。
AI技術の進化により、誰でも高性能なAIを手軽に利用できる時代が到来しました。技術の民主化が進み、個人や中小企業でもAIを活用したサービスやツールを簡単に開発・利用できるようになっています。弊社でも、AIを活用したサービスとして「AIテクニカルコードレビュー」や「AIデバッグ」を提供しており、これらのサービスは開発プロセスの効率化と品質向上に大いに貢献しています。今後もAI技術の進化に伴い、さらに多様なサービスが登場し、私たちの生活やビジネスに新たな可能性をもたらすことが期待されます。
▼関連記事はこちら
AIを使ってコードレビューをやってみた|Sqripts
AIの目で見るバグの世界|Sqripts