こんにちは、バックエンドエンジニアのまさです。
AI技術の急速な進化に伴い、従来のキーワード検索では対応できない「意味的な類似性」に基づく検索ニーズが急増しています。本記事では、オープンソースRDBMSであるPostgreSQLにpgvector拡張を組み込むだけで、簡単にベクトル検索システムを構築する方法を解説します。 ベクトル検索とは、文章を数値ベクトルに変換して抽象的な意味を検索する技術であり、キーワード依存型の検索では捉えきれない「ユーザーが本当に求めている意図」を、高い精度で汲み取れる検索手法です。 この記事では、ベクトル検索をPostgreSQLに組み込む方法を、ハンズオン形式で環境構築を進めながら説明していきます。
ベクトル検索とは
3分で分かるベクトル検索の仕組み
従来のキーワード検索は、文字通りキーワードが一致するかどうかで検索結果を返します。しかし、言葉の表現は多様であり、ユーザーの意図と完全に一致するキーワードが使われるとは限りません。そこで登場するのがベクトル検索です。
ベクトル検索は、テキストや画像などのデータを、数値の集まりであるベクトルに変換します。このベクトルは、元のデータの意味的な特徴を捉えており、類似した意味を持つデータは、ベクトル空間上で近い位置に配置されます。
具体的な仕組み:
- エンベディング: テキスト(質問や文章)を、事前に学習済みのAIモデル(例:OpenAIのtext-embedding-ada-002)を用いて、数値ベクトルに変換します。この処理をエンベディングと呼びます。
- ベクトルデータベース: エンベディングされたベクトルをデータベース(この例ではPostgreSQL + pgvector)に格納します。
- 類似度計算: 検索クエリも同様にベクトルに変換し、データベース内のベクトルとの類似度を計算します。類似度の高いベクトルを持つデータが、検索結果として返されます。
例:
「猫が好きな人におすすめの映画は?」という質問をベクトル検索にかけると、「猫」というキーワードが含まれていなくても、「猫が登場する映画」「猫を飼っている人が主人公の映画」など、意味的に関連性の高い映画が検索結果として表示される可能性があります。
つまり、ベクトル検索は、キーワードに縛られず、意味に基づいた柔軟な検索を実現する技術なのです。
PostgreSQL採用の5大メリット
ベクトル検索システムを構築する上で、PostgreSQLを採用するメリットは多岐にわたります。以下に主な5つのメリットを挙げます。
- 拡張性: pgvector拡張により、PostgreSQLにベクトル検索機能を追加できます。既存のデータベース環境を大きく変更する必要はありません。
- コスト効率: オープンソースであるため、高額なライセンス費用は不要です。必要なハードウェアリソースのみで運用できます。
- 信頼性: PostgreSQLは長年の実績を持つ堅牢なRDBMSであり、高い信頼性と安定性を誇ります。
- 標準SQL対応: 既存のSQLクエリと組み合わせて、複雑な検索処理を記述できます。
- コミュニティサポート: 世界中に活発なコミュニティが存在し、豊富な情報やサポートが得られます。
従来検索とのパフォーマンス比較表
| 検索方式 | 検索精度 | 検索速度 (データ量依存) | 柔軟性 | 備考 |
|---|---|---|---|---|
| キーワード検索 | キーワード一致に依存。曖昧な表現や同義語に弱い。 | 高速 | 低い。キーワードの厳密な一致が必要。 | シンプルな検索には適している。 |
| ベクトル検索 | 意味的な類似性に基づくため、キーワードに依存しない。高い精度を実現。 | データ量に依存。インデックス構造で高速化可能。 | 高い。ユーザーの意図を汲み取った柔軟な検索が可能。 | 大量のデータに対しては、適切なインデックス設計が重要。 |
| 全文検索 | キーワード検索より高度な検索が可能だが、意味理解は限定的。 | データ量に依存。 | 中程度。 | 日本語の形態素解析など、言語依存の処理が必要な場合がある。 |
補足:
- パフォーマンスは、データ量、ハードウェア、インデックス設計などに大きく左右されます。
- 上記比較表はあくまで一般的な傾向を示すものであり、実際のパフォーマンスは環境によって異なります。
専用のベクトルデータベースとの比較
専用のベクトルデータベース(例: Chroma, FAISS, Pinecone)とPostgreSQLの拡張機能であるpgvectorは、それぞれ異なる強みを持っています。ここでは、pgvectorと専用ベクトルデータベースとの違いや、それぞれのメリット・デメリットを解説します。
pgvectorの特徴
pgvectorは、PostgreSQLにベクトル検索機能を追加する拡張機能です。以下が主な特徴です:
- リレーショナルデータとの統合:ベクトルデータと従来のリレーショナルデータを同じデータベースで管理可能。
- 低コスト導入:既存のPostgreSQL環境に拡張機能として追加するだけで利用可能。
- ACID準拠:トランザクション管理やセキュリティ機能をそのまま利用可能。
専用ベクトルデータベースの特徴
専用ベクトルデータベース(例: Chroma, FAISS, Pinecone)は、ベクトル検索に特化した設計がされています。以下が主な特徴です:
- 高速検索:高次元ベクトルに最適化されたインデックス設計(例: HNSW, IVF)。
- スケーラビリティ:分散システムによる水平スケーリングが容易。
- 多様なデータ形式対応:画像、音声、動画などの非構造化データも効率的に処理可能。
比較表
| 項目 | pgvector | 専用ベクトルデータベース(例: Chroma, FAISS) |
|---|---|---|
| 導入コスト | 低い(既存PostgreSQL環境で利用可能) | 高い(新規インフラ構築が必要) |
| 速度(大規模データ) | 中程度(PostgreSQL依存) | 高速(専用設計による最適化) |
| スケーラビリティ | 垂直スケール(ハードウェア増強が必要) | 水平スケール(分散システム対応) |
| 統合性 | 高い(SQLクエリでリレーショナルデータと統合) | 低い(別途APIやミドルウェアが必要) |
| ユースケース | 小〜中規模データ、既存RDBMSとの統合 | 大規模データ、高速検索が求められるAI/MLワークフロー |
| 学習コスト | 低い(PostgreSQLユーザーに馴染みやすい) | 中〜高(新しいツールやAPIの習得が必要) |
pgvectorのメリットとデメリット
- メリット
- 簡単な導入手順:PostgreSQL環境に拡張機能としてインストールするだけで利用可能。
- 低コスト運用:既存インフラを活用できるため、新たなサーバー構築が不要。
- SQL統合性:従来のSQLクエリと組み合わせてハイブリッド検索が可能。
- デメリット
- パフォーマンス限界:大規模データセットや超高次元ベクトルでは専用VectorDBに劣る。
- 水平スケーリング非対応:PostgreSQL自体が分散システムに最適化されていないため、大量トラフィックには不向き。
- 機能制約:画像や音声など非構造化データへの対応は限定的。
専用ベクトルデータベースのメリットとデメリット
- メリット
- 高速な類似検索:HNSWやIVFなど、高度なインデックスアルゴリズムを採用。
- 大規模データ対応:分散システムによる水平スケーリングで数十億件以上のベクトル処理も可能。
- 柔軟性:画像、音声、動画など多様なデータ形式に対応。
- デメリット
- 導入・運用コストが高い:新たなインフラ構築や運用管理が必要。
- 学習コストが高い:新しいツールやAPIの習得が求められる。
- 統合性が低い:従来のRDBMSとの連携には追加開発が必要。
選択基準
- pgvectorを選ぶべきケース
- 既存のPostgreSQL環境を活用したい場合
- 中小規模のプロジェクトでコスト効率を重視する場合
- リレーショナルデータとの統合性が重要な場合
- 専用VectorDBを選ぶべきケース
- 数千万〜数億件以上の大規模ベクトル検索を行う場合
- 非構造化データ(例: 画像、音声)の処理が必要な場合
- 高速性とスケーラビリティを最優先する場合
pgvectorは、PostgreSQLユーザーにとって手軽かつコスト効率の良い選択肢であり、中小規模プロジェクトには最適です。一方、専用VectorDBは、大規模かつ複雑なAI/MLワークフローにおいて圧倒的なパフォーマンスを発揮します。用途や要件に応じて、それぞれの特性を活かした選択を行うことが重要です。
環境構築
本章ではハンズオン形式でPostgreSQLコンテナのセットアップから、Streamlitを用いたフロントエンドの構築、そしてそれらを連携させるDocker環境の設定まで、必要な手順をわかりやすく解説します。この章の手順に従うことで、pgvectorを用いた簡単なベクトル検索システムを構築できます。
環境構成
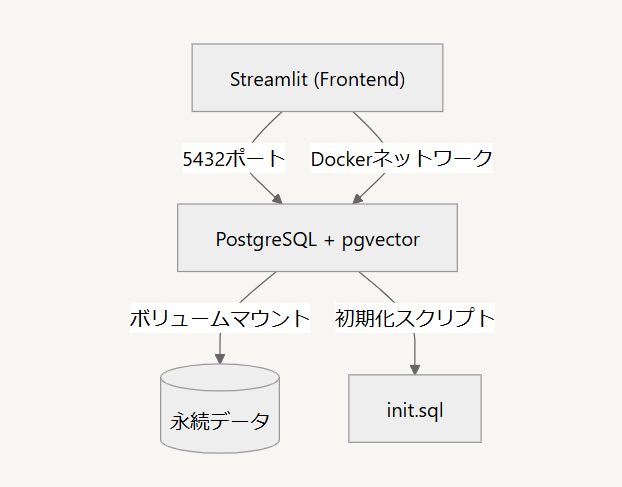
上記のように非常にシンプルな構成をdocker composeで構築します。
ディレクトリ構成は以下のようになります。
├── .streamlit
│ └── secrets.toml *# DB接続情報*
├── docker-compose.yml
├── postgres
│ ├── Dockerfile *# PG拡張機能インストール*
│ └── initdb
│ └── init.sql *# テーブル定義*
└── streamlit
├── Dockerfile *# Python環境構築*
├── app.py *# メインアプリ*
├── embeddings.py *# ベクトル生成ロジック*
├── requirements.txt
└── seed.py *# テストデータ生成*
PostgreSQLコンテナの環境構築
PostgreSQLのデータベースを起動するコンテナ上に初期設定用のSQLファイルを作成します。
CREATE EXTENSION IF NOT EXISTS vector;
-- サンプルテーブル作成(必要に応じてカスタマイズ)
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
title TEXT,
content TEXT,
embedding VECTOR(1024)
);
CREATE INDEX ON documents USING hnsw (embedding vector_cosine_ops);
Streamlitコンテナの環境構築
メイン処理となるpythonコードを記述したファイルを作成します。
import streamlit as st
import pandas as pd
import numpy as np
from datetime import datetime
import psycopg2
from psycopg2.extras import execute_values
from sqlalchemy.sql import text
from streamlit.logger import get_logger
from embedding import Embedding
logger = get_logger(__name__)
embedding = Embedding()
# ページ設定
st.set_page_config(
page_title="Vector Database Demo",
page_icon="🔍",
layout="wide"
)
def get_embedding(text):
return embedding.get_embedding([text])[0]
# データベース接続関数
def get_connection():
return st.connection('postgresql', type='sql')
# メインアプリケーション
def main():
st.title("📊 Vector Database Demo")
# サイドバーでの操作選択
operation = st.sidebar.selectbox(
"操作を選択",
["データ表示", "データ追加", "ベクトル検索"]
)
if operation == "データ表示":
show_data()
elif operation == "データ追加":
add_data()
elif operation == "ベクトル検索":
vector_search()
def show_data():
st.header("📋 登録データ一覧")
conn = get_connection()
# データ取得
query = "SELECT id, title,content FROM documents LIMIT 100"
df = conn.query(query, ttl=0)
if not df.empty:
st.dataframe(df)
else:
st.info("データが登録されていません")
def add_data():
st.header("➕ データ追加")
# 入力フォーム
with st.form("data_form"):
title = st.text_input("タイトルを入力")
content = st.text_area("テキストを入力")
submitted = st.form_submit_button("登録")
if submitted and content:
conn = get_connection()
# サンプルとして、ランダムな1536次元ベクトルを生成
# 実際のアプリケーションでは、適切なエンベッディングモデルを使用する
embedding = get_embedding(title + " " + content)
# データ登録
query = text("""
INSERT INTO documents (title, content, embedding)
VALUES (:title, :content, :embedding)
""")
params = {"title": title, "content": content, "embedding": embedding}
try:
with conn.session as session:
session.execute(query, params)
session.commit()
st.success("データを登録しました")
except Exception as e:
st.error(f"エラーが発生しました: {str(e)}")
def vector_search():
st.header("🔍 ベクトル検索")
search_text = st.text_input("検索テキストを入力")
k = st.slider("表示件数", min_value=1, max_value=10, value=5)
if st.button("検索") and search_text:
# サンプルとして、ランダムなクエリベクトルを生成
# 実際のアプリケーションでは、入力テキストを適切にエンベッディング
query_vector = get_embedding(search_text)
conn = get_connection()
# コサイン類似度による検索
query = """
SELECT title,content, 1 - (embedding <-> :query_vector) as similarity
FROM documents
ORDER BY embedding <-> :query_vector
LIMIT :k
"""
params = {"query_vector": str(query_vector), "k": k}
try:
df = conn.query(query, params=params, ttl=0)
if not df.empty:
# 結果表示
for _, row in df.iterrows():
with st.expander(f"{row['title']} 類似度: {row['similarity']:.4f}"):
st.write(row['content'])
else:
st.info("検索結果が見つかりませんでした")
except Exception as e:
st.error(f"検索中にエラーが発生しました: {str(e)}")
# アプリケーション実行
if __name__ == "__main__":
main()
テキストの埋め込み処理を行うpythonコードを記述したファイルを作成します。
今回の例ではデフォルトで埋め込み用のモデルにmultilingual-e5-largeを使用するように設定しています。このモデルを変更することで検索時の傾向等を変えることが可能です。
intfloat/multilingual-e5-large · Hugging Face
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
class Embedding:
def __init__(self, model_name: str = 'intfloat/multilingual-e5-large'):
self.model_name = model_name
self.load_model()
def load_model(self):
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name)
self.model = AutoModel.from_pretrained(self.model_name)
def average_pool(
self,
last_hidden_states: Tensor,
attention_mask: Tensor
) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
def get_embedding(self, input_texts: list[str]) -> list[float]:
batch_dict = self.tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = self.model(**batch_dict)
embeddings = self.average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
return F.normalize(embeddings, p=2, dim=1).tolist()
初期データの投入を行うpythonコードを記述したファイルを作成します。
単純にタイトルと内容をならべ、それらをデータベースに埋め込み表現と共に保存しています。
import psycopg2
import numpy as np
from psycopg2.extras import execute_values
from embedding import Embedding
test_data = [
{
"title": "Dockerコンテナのベストプラクティス2025年版",
"content": "Dockerコンテナを本番環境で効率的に運用するためのベストプラクティスを解説します。イメージサイズの最適化、セキュリティ対策、ネットワーク設定、ボリューム管理など、実践的なトピックを網羅的にカバーします。マルチステージビルドの活用方法や、環境変数の適切な管理方法についても詳しく説明します。"
},
{
"title": "PyTorchによる深層学習モデルの最適化手法",
"content": "PyTorchを使用した深層学習モデルのパフォーマンス最適化について解説します。バッチサイズの調整、学習率スケジューリング、データローダーの最適化、GPUメモリの効率的な使用方法など、実践的な最適化テクニックを紹介します。"
},
{
"title": "マイクロサービスアーキテクチャの設計パターン",
"content": "マイクロサービスアーキテクチャを採用する際の主要な設計パターンについて解説します。サービス間通信、データ一貫性の確保、障害対策、モニタリング戦略など、実装時の重要なポイントを詳しく説明します。"
},
{
"title": "Kubernetes運用管理の実践ガイド",
"content": "Kubernetesクラスタの効率的な運用管理方法について解説します。リソース管理、オートスケーリング、モニタリング、セキュリティ対策など、実運用で必要となる知識を体系的に説明します。"
},
{
"title": "効率的なデータベースインデックス設計",
"content": "リレーショナルデータベースにおけるインデックス設計のベストプラクティスを解説します。クエリパフォーマンスの最適化、インデックス選択の基準、メンテナンス戦略など、実践的なアプローチを紹介します。"
},
{
"title": "GraphQLによるモダンAPIの構築",
"content": "GraphQLを使用したAPIの設計と実装について解説します。スキーマ設計、リゾルバの実装、N+1問題の解決、キャッシュ戦略など、実践的な開発手法を紹介します。"
},
{
"title": "CI/CDパイプラインの自動化戦略",
"content": "継続的インテグレーション/デリバリーパイプラインの効率的な構築方法について解説します。テスト自動化、デプロイ戦略、品質管理、モニタリングなど、実践的な自動化手法を紹介します。"
},
{
"title": "セキュアなWebアプリケーション開発",
"content": "Webアプリケーションのセキュリティ対策について包括的に解説します。XSS対策、CSRF対策、認証・認可の実装、セキュアなセッション管理など、重要なセキュリティ考慮事項を説明します。"
},
{
"title": "効率的なキャッシュ戦略の実装",
"content": "Webアプリケーションにおけるキャッシュ戦略の設計と実装について解説します。CDN、ブラウザキャッシュ、アプリケーションキャッシュ、データベースキャッシュなど、多層的なキャッシュ戦略を紹介します。"
},
{
"title": "大規模データ処理のベストプラクティス",
"content": "大規模データ処理システムの設計と実装について解説します。バッチ処理、ストリーム処理、データパイプライン、スケーラビリティ確保など、実践的なアプローチを紹介します。"
},
{
"title": "ReactとTypeScriptによるフロントエンド開発",
"content": "ReactとTypeScriptを組み合わせた最新のフロントエンド開発手法について解説します。型安全な開発、コンポーネント設計、状態管理、パフォーマンス最適化など、実践的な開発テクニックを紹介します。"
},
{
"title": "AWSでのスケーラブルなインフラ構築",
"content": "AWSを使用したスケーラブルなインフラストラクチャの構築方法について解説します。オートスケーリング、負荷分散、障害対策、コスト最適化など、クラウドインフラの設計ポイントを説明します。"
},
{
"title": "効率的なログ管理とモニタリング",
"content": "分散システムにおけるログ管理とモニタリングの実践的アプローチについて解説します。ログ収集、分析、可視化、アラート設定など、効果的な運用監視の方法を紹介します。"
},
{
"title": "マイクロフロントエンドアーキテクチャの実装",
"content": "マイクロフロントエンドアーキテクチャの設計と実装について解説します。モジュール分割、統合戦略、ルーティング、状態管理など、フロントエンド開発の新しいアプローチを紹介します。"
},
{
"title": "NoSQLデータベースの設計パターン",
"content": "NoSQLデータベースを使用する際の効果的な設計パターンについて解説します。データモデリング、クエリ最適化、スケーリング戦略など、実践的な使用方法を紹介します。"
},
{
"title": "機械学習モデルの本番環境デプロイ",
"content": "機械学習モデルを本番環境にデプロイする際の実践的アプローチについて解説します。モデルのバージョン管理、スケーリング、モニタリング、再学習戦略など、運用上の重要ポイントを説明します。"
},
{
"title": "Terraformによるインフラのコード化",
"content": "Terraformを使用したインフラストラクチャのコード化について解説します。リソース管理、モジュール設計、状態管理、チーム開発など、IaCの実践的な適用方法を紹介します。"
},
{
"title": "効率的なAPIバージョニング戦略",
"content": "WebAPIのバージョニング戦略について実践的な方法を解説します。バージョン管理手法、下位互換性の確保、マイグレーション戦略など、長期的な API 運用のポイントを説明します。"
},
{
"title": "セキュアなマイクロサービス間通信",
"content": "マイクロサービス環境におけるセキュアな通信方法について解説します。認証、認可、暗号化、証明書管理など、サービス間通信のセキュリティ確保方法を説明します。"
},
{
"title": "効率的なデータベースマイグレーション",
"content": "大規模データベースのマイグレーション戦略について解説します。ダウンタイム最小化、データ整合性確保、ロールバック計画など、安全なマイグレーションの実施方法を紹介します。"
}
]
def insert_test_data():
conn = psycopg2.connect(
dbname="vectordb",
user="postgres",
password="postgres",
host="postgres",
port="5432"
)
cur = conn.cursor()
embedding = Embedding()
for data in test_data:
# サンプルとして1536次元のランダムベクトルを生成
emb = embedding.get_embedding([data["title"] + " " + data["content"]])[0]
cur.execute(
"INSERT INTO documents (title, content, embedding) VALUES (%s, %s, %s)",
(data["title"], data["content"], emb)
)
conn.commit()
cur.close()
conn.close()
if __name__ == "__main__":
insert_test_data()
データベースとの接続定義を記述したファイルを作成します。
[connections.postgresql]
dialect = "postgresql"
host = "postgres"
port = 5432
database = "vectordb"
username = "postgres"
password = "postgres"
依存ライブラリを記述したファイルを作成します。
SQLAlchemy==2.0.35
streamlit==1.32.0
pandas==2.2.0
numpy==1.26.0
psycopg2-binary==2.9.9
torch==2.6.0
transformers==4.48.2
Docker環境のセットアップ
まずはpostgresのDockerfileから作成をしていきます。
postgresベースのイメージにpgvectorのインストール処理を追加します。
FROM postgres:16.3
# pgvectorインストール
RUN apt-get update && \\
apt-get install -y \\
build-essential \\
git \\
postgresql-server-dev-16
RUN git clone <https://github.com/pgvector/pgvector.git> /tmp/pgvector && \\
cd /tmp/pgvector && \\
make && \\
make install && \\
rm -rf /tmp/pgvector
続けてStreamlitのDockerfileを作成します。
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
CMD ["streamlit", "run", "./streamlit/app.py", "--server.port=8501"]
最後にこれらのコンテナを束ねて管理するdocker-compose.ymlを作成します。
version: "3.9"
services:
postgres:
build: ./postgres
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
POSTGRES_DB: vectordb
volumes:
- postgres_data:/var/lib/postgresql/data
- ./postgres/initdb:/docker-entrypoint-initdb.d
ports:
- "5432:5432"
networks:
- app-network
streamlit:
build: ./streamlit
volumes:
- .:/app
environment:
- STREAMLIT_SERVER_PORT=8501
ports:
- "8501:8501"
depends_on:
- postgres
networks:
- app-network
volumes:
postgres_data:
networks:
app-network:
driver: bridge
動作確認
起動確認
以下のコマンドでコンテナのビルドを行います。
docker compose build
以下のコマンドでコンテナの起動を行います。
docker compose up -d
ブラウザで以下のアドレスにアクセスします。
最初はモデルを読み込むためロード中となり、下記のような画面が表示されるかと思いますが
その後このような表示になれば、サーバーの起動に成功しています。

初期データの投入
データベースに初期データを投入する為、コンテナ上でコマンドを実行します。 まずはコンテナの状態の確認を行います。
$ docker compose ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
pgvector-postgres-1 pgvector-postgres "docker-entrypoint.s…" postgres 2 hours ago Up 2 hours 0.0.0.0:5432->5432/tcp, :::5432->5432/tcp
pgvector-streamlit-1 pgvector-streamlit "streamlit run ./str…" streamlit 2 hours ago Up 2 hours 0.0.0.0:8501->8501/tcp, :::8501->8501/tcp
上記で出力されたコンテナの内、streamlitのコンテナ上で以下のようにしてコマンドを実行します。
$ docker exec -it pgvector-streamlit-1 python streamlit/seed.py
コマンド実行後に再度ブラウザで以下のアドレスにアクセスします。
http://localhost:8501/

投入したデータが一覧で表示されるようになりました。
Vector検索の確認
先ほどアクセスした画面の「操作を選択」から「ベクトル検索」を選択します。
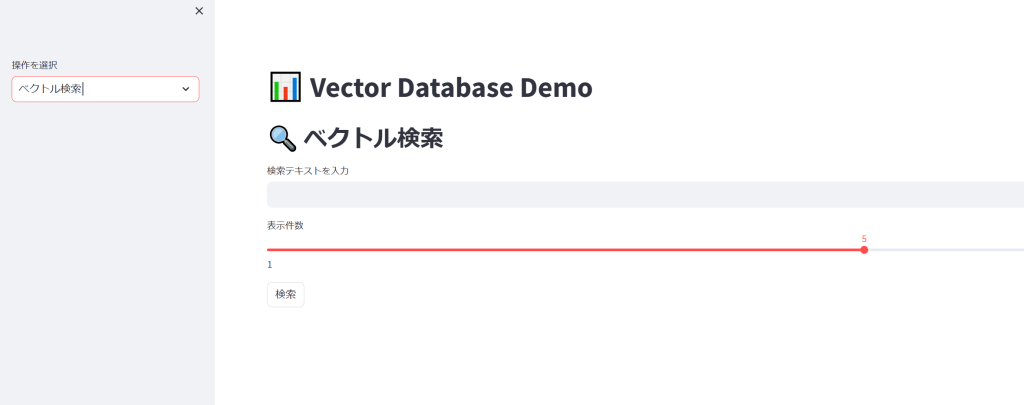
上記のような画面が表示されるかと思います。
試しにこちらの検索テキストに「MySQL」と入力して検索してみます。
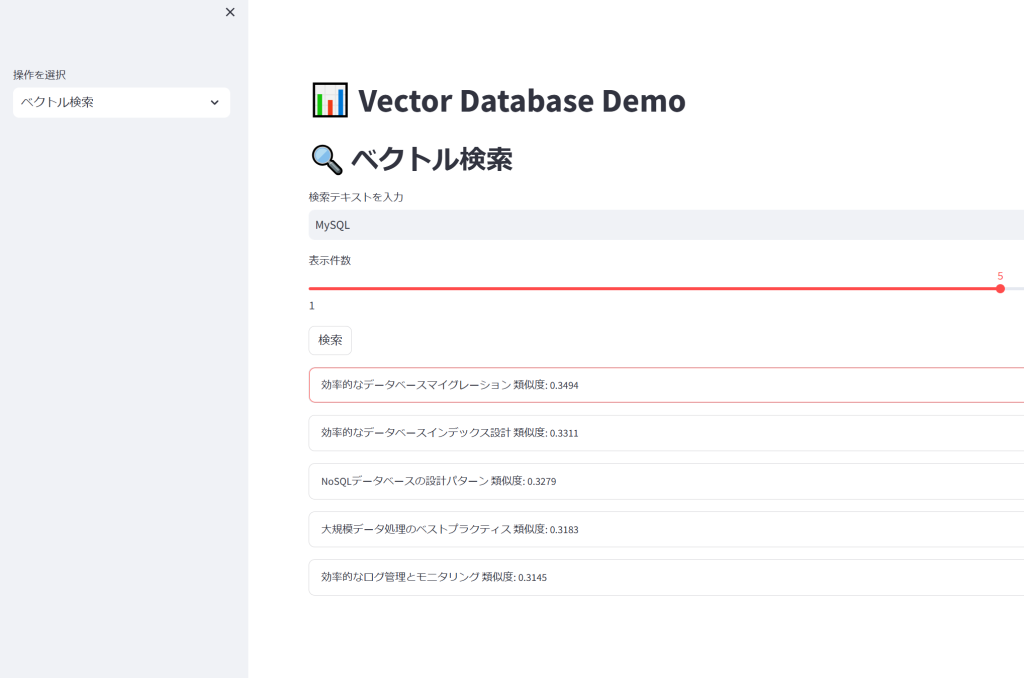
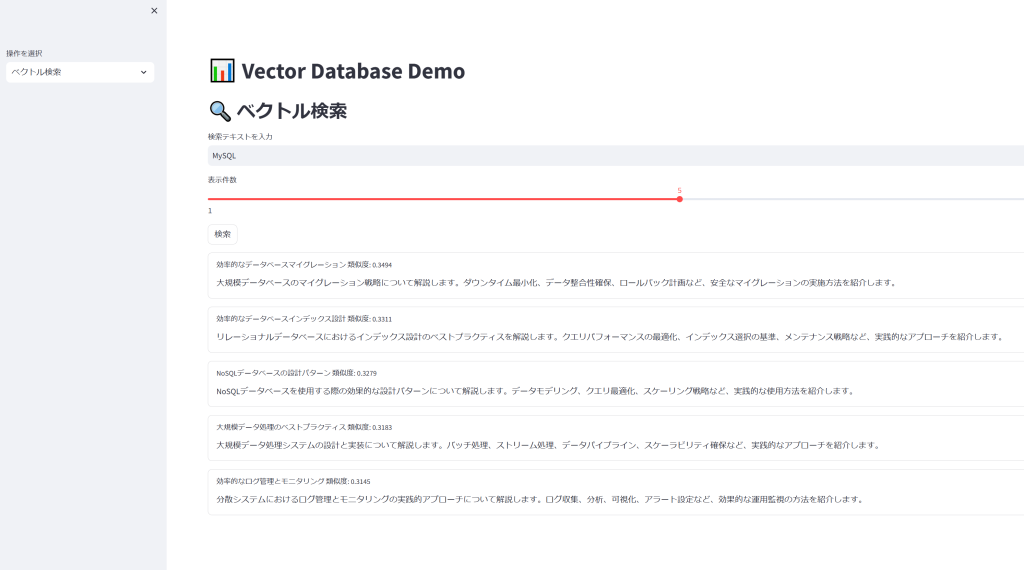
上記のように結果が表示されました。内容としては以下のようなものですが、もちろん本文に「MySQL」という文言はありません。
内容の指向性や意味などからもっとも類似度の高い内容順に並べることができていることが確認できます。
おわりに
本記事で実践したPostgreSQLベクトル検索システムの構築は、AI時代のデータ活用における重要な第一歩です。従来のリレーショナルデータベースの枠組みを超え、意味理解を組み込んだ次世代検索技術を、既存インフラで実現する手法を具体例と共に解説しました。 本格的な導入を検討される方は、まずはpgvector公式ドキュメントとE5モデルに関しての記事の精読をお勧めします。実際のプロダクション環境では、インデックス再構築戦略とメモリ最適化が成否を分ける鍵となります。
最後に、本記事が皆様のAI/MLプロジェクト推進の一助となれば幸いです。