




こんにちは、セキュリティエンジニアの河村です。
今回はオライリー出版「セキュリティエンジニアのための機械学習」の書評をお届けします。
本書は、セキュリティエンジニアがこれからの時代に必要とされる機械学習の基礎的な考え方に入門するための書籍です。
■セキュリティエンジニアのための機械学習
(Chiheb Chebbi 著、新井 悠、一瀬 小夜、黒米 祐馬 訳/O’REILLY JAPAN)

本の概要
本書で扱われている内容は幅広く、データサイエンスの基本(たとえばPandasの操作方法)から、SVM(サポートベクターマシン)などの古典的な機械学習(以下「古典ML」)、さらにCNN(畳み込みニューラルネットワーク)といったディープラーニング、Deep Q-Networkに代表される強化学習までをカバーしています。
そのため、理論を厳密に学ぶための専門書というよりも、「機械学習とは何か」を広くイメージできるよう構成された入門書となっています。
もちろん、ディープラーニングや強化学習といった最先端の内容には専門性が求められ、すべてを完全に理解するのは簡単ではありません。
しかしながら、たとえば「特徴量」や「正規化」といった基本的な考え方は、機械学習全体に共通するものであり、理系出身でなくても、本書で紹介される具体例を通じて体感することで、概念的な理解を深めることが可能です。※1

なお、本書は内容が多岐にわたるため、本書評は前後編に分けて掲載します。第一回となる本稿では、古典的な機械学習を中心とした第3章までの内容について、概要・得られる知見・ブログ執筆者である私の所感を整理して紹介します。
続く第二回では、ディープラーニングや最先端の攻撃手法など、より発展的な内容について取り上げる予定です。
それでは次節より、本書の内容を章ごとに追っていきます。
本書がお勧めできる読者層
| 読者層 | おすすめ度 | コメント |
|---|---|---|
| 機械学習・統計の知識があり、 セキュリティ分野に応用したい方 | ★★★★★ | 理論と実践が噛み合い、応用力が高まります。 |
| サーバ監視業務に携わっている方 | ★★★★★ | 実務に直結する内容が豊富です。 |
| セキュリティ分野のトレンドを 広く浅く把握したい方 | ★★★★★ | 最新情報を網羅的に知ることができます。 |
| セキュリティ関連の ソフトウェア開発者 | ★★★★☆ | 実装のヒントが得られ、開発に活かせます。 |
| ペンテスター | ★★★★☆ | マルウェアや攻撃手法の知識が深まります。 |
| IoTテスター | ★★☆☆☆ | 新しい攻撃手法の理解のヒントにはなりますが、実用性はやや限定的です。 |
| 初心者セキュリティエンジニア | ★★☆☆☆ | 統計の基礎を先に学ぶことを推奨。やや難易度が高めです。 |
(※1) 雰囲気だけでもいいので機械学習の理論のイメージを掴むことが大事な理由
例え理論を完全に理解出来なかったとしても、機械学習のプロセスやアルゴリズムの性質を知ることで、ブラックボックスになりがちな機械学習・AI関連の技術で行われてることにもある程度の想像力が付くようになります。 機械学習・AI分野の進歩は非常に早く、既知の技術が一年で時代遅れになることもざらです。しかし、セキュリティ業務を行うものはテキストに乗ってない脆弱性だからといって見落とすことは許されません。つまり今まで以上に想像力と慧眼(けいがん)が重要になってきてると言えます。 現在進行形で脅威度が増してるLLMに対するハッキング(https://genai.owasp.org/resource/owasp-top-10-for-llm-applications-2025/)の手法などの理解には、本書で記載されてるようなデータ分析・機械学習の考え方は非常に重要です。できるだけ初心者の方にもわかりやすく伝えるつもりなので、少しでも理解の手伝いになれればと思っております。
章ごとの概要
章ごとに内容の難易度を主観で付けさせてもらいます。以下が難易度の指標です。
★☆☆ 基本的な内容
★★☆ 重要な内容、基本情報レベルの数学・技術要素あり
★★★ かなり発展的な内容
第1章 情報セキュリティエンジニアのための機械学習入門(★☆☆)
序章と第1章では、近年、機械学習やAIがセキュリティ分野でますます重要な役割を果たしていることが説明されています。
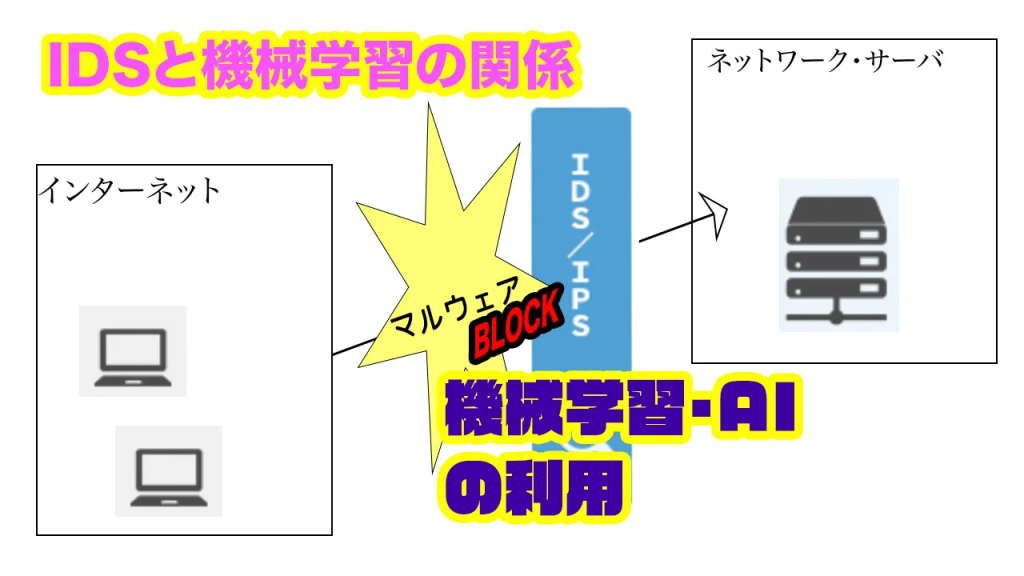
具体例として取り上げられているのが、侵入検知システム(IDS)※2における異常検知です。IDSでは、通常とは異なる挙動(異常値)を識別する際に、機械学習の手法が非常に効果的であるとされています。これにより、ルールベースでは検出しきれない未知の攻撃への対応が可能になるといった利点があるのです。
こうした理論的な説明を踏まえ、第2章以降では実際にコードを動かしながら、より具体的な手法や実装を学べる構成となっています。
※2 侵入検知システム(IDS)とは、ネットワークやシステムへの不正アクセスや異常な挙動をリアルタイムで検知するセキュリティ対策の仕組みです。
また、本書で紹介されているサンプルコードは、Google Colaboratory上で実行できるようになっています。実行環境の構築方法についても、序章にて丁寧に説明されています。
ただし、ブログ執筆者である私が実際に試したところ、Google Colaboratoryの仕様変更などの影響で、一部のコードがそのままでは再現しづらいケースが見られました。そのため、以下のような代替手段を検討してもよいでしょう。
実行環境の選択肢
- ローカル環境で Jupyter Notebook※3を使用する 特に GPU を搭載した PC をお持ちの場合は、ローカル環境の構築が有効です。本書のほとんどのサンプルコードはそのまま動作します。 環境構築の詳細については、以下のようなサイトが参考になります。
https://ai-inter1.com/jupyter-notebook/ - AWS や GCP などのクラウドサービスを利用する 本書のコードは比較的軽量であり、10年ほど前のゲーミングノートPCでも動作可能です。しかし、より発展的な内容に取り組む場合、高性能なPCが必要になるため、クラウドサービスを活用したほうがコスト面で有利になることがあります。
- Google Colaboratory の有料版を利用する ブログ執筆者である私は未検証ですが、有料版では無料版の制限(インスタンスの維持時間、メモリ容量、ディスク容量など)が緩和されます。ただし、AWS や GCP のような高い拡張性はなく、コストパフォーマンスの面でもやや劣るため、あくまで学習用途として割り切って利用するのがよいと考えられます。
※3 Jupyter Notebookは、コードの実行・可視化・ドキュメント作成を一つのインターフェースで行える、データ分析や機械学習に特化した対話型開発環境です。
機械学習によるモデル開発は以下のようなステップになります:
🗃 データセットの作成
↓
📥 データセットの読み込み・前処理
↓
🔍 探索的データ分析・特徴量エンジニアリング
↔️
🤖 モデルの訓練と評価
↓
🚀 デプロイ2章以降ではこの流れも体験出来ます。
※ 以下の図が更に詳細です
https://www.researchgate.net/figure/Machine-learning-workflow_fig3_360998525
個人的な所感として、初心者が機械学習の学習で最初に最もつまずきやすいのは「環境構築」ではないかと感じています。実際、私自身も本書のサンプルコードを再現する際に、多くの困難に直面しました。
コードが動作しない原因を調べながら、環境依存の問題を解決していく過程では、Linux の基本操作、Python のパッケージ管理、ソフトウェアのバージョン管理など、セキュリティエンジニアとして重要なスキルを体系的に学ぶことができます。
確かに手間はかかりますが、その分得られる知見は大きく、将来的な技術的応用力にもつながります。ぜひ本書の内容を足がかりに、積極的にチャレンジしていただければと思います。
「セキュリティエンジニアのための機械学習」より
第2章 フィッシングサイトと迷惑メールの検出(★★☆)
この章ではフィッシングサイトや迷惑メールの検知器の開発を通して、機械学習・ディープラーニングの初歩である、ロジスティック回帰、決定木のアルゴリズム、NLP(自然言語処理)の技術を学びつつ、サンプルコードを通して実際に実装して学びます。
機械学習・ディープラーニングのアルゴリズムは大雑把に以下のように進化しました。
【統計モデル】
└─ ロジスティック回帰(線形分類の基本)
【単体学習器】
├─ 決定木(ルールベースの非線形モデル)
├─ k-NN(距離ベースの分類器)
└─ SVM(マージン最大化)
【アンサンブル学習】
├─ ランダムフォレスト(決定木×多数決)
└─ 勾配ブースティング(決定木×逐次学習)
└─ XGBoost / LightGBM / CatBoost など
--------------------------- ↑ ここまでが古典ML ---------------------------------
--------------------------- ↓ ここからがディープラーニング -----------------------
【ニューラルネットワーク系】
└─ ニューラルネット(多層パーセプトロン)
└─ 深層学習(DNN, CNN, RNN)→ 2010年頃の初期のディープラーニング
└─ BERT / GPT などの大規模言語モデル → モダンなディープラーニング
※ より詳しくは以下リンクの図を参照してください
https://www.researchgate.net/figure/Development-history-of-classical-machine-learning-algorithms-since-the-1930s_fig2_360998525
ロジスティック回帰や決定木は機械学習の基本ではありますが、ベースとなる理論に線型代数、確立・統計の要素があったりと、特に文系の方にとって決して容易な内容ではございません。数学的な背景を知りたい方は以下のサイトなどを参照してください。https://bellcurve.jp/statistics/course/26934.html
「セキュリティエンジニアのための機械学習」より

フィッシングサイト検出器の開発(ロジスティック回帰・決定木)
UCI Machine Learning Repositoryのフィッシングサイトのデータセットを用いて、演習を行います(※ 参考 https://archive.ics.uci.edu/dataset/327/phishing+websites)。ここには各サイトのヘッダの有無、アドレスがIPアドレスか否かなどの特徴量※4が0、1で記されています。
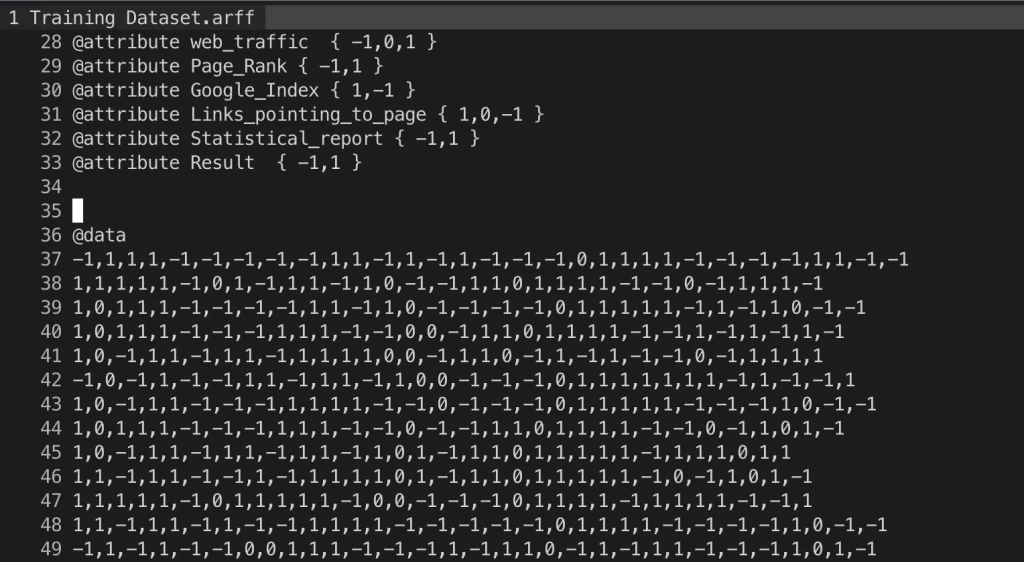
※4 特徴量とは、機械学習モデルが判断や予測を行うための入力データの要素(情報の断片)です。

この数字を行列・テンソルとしてプログラムが扱えるように加工することで、初めてロジスティック回帰を初めとする機械学習のアルゴリズムが実行可能となります。
ここではsklearn、optuna等のツールを用います。
sklearnとoptunaについて
sklearnは機械学習のアルゴリズムが複数搭載されたPythonライブラリです。今回取り扱ってるロジスティック回帰などはsklearnを用いずに実装することも可能なので、理解を深めたい方は調べてみるとよいと思います。
※ 参考 https://qiita.com/phyblas/items/375ab130e53b0d04f784
optunaは「ハイパーパラメータのチューニング」を行うためのライブラリです。ハイパーパラメータのチューニングでは機械学習で用いられるモデルの構造を調整することで、精度や速度を大幅に改善できるため、非常に重要な工程です。
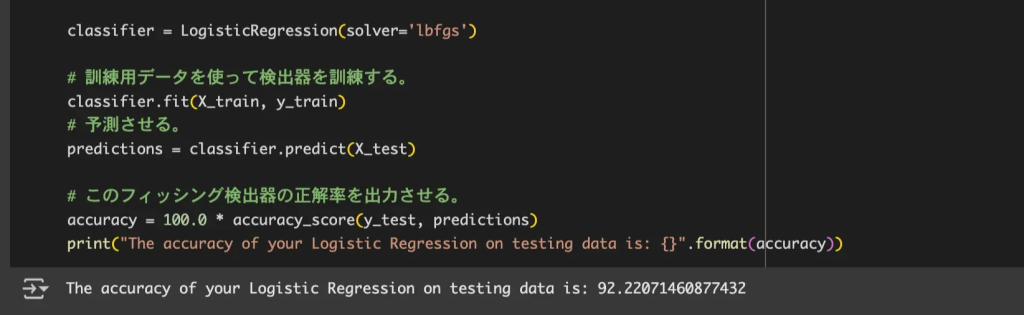
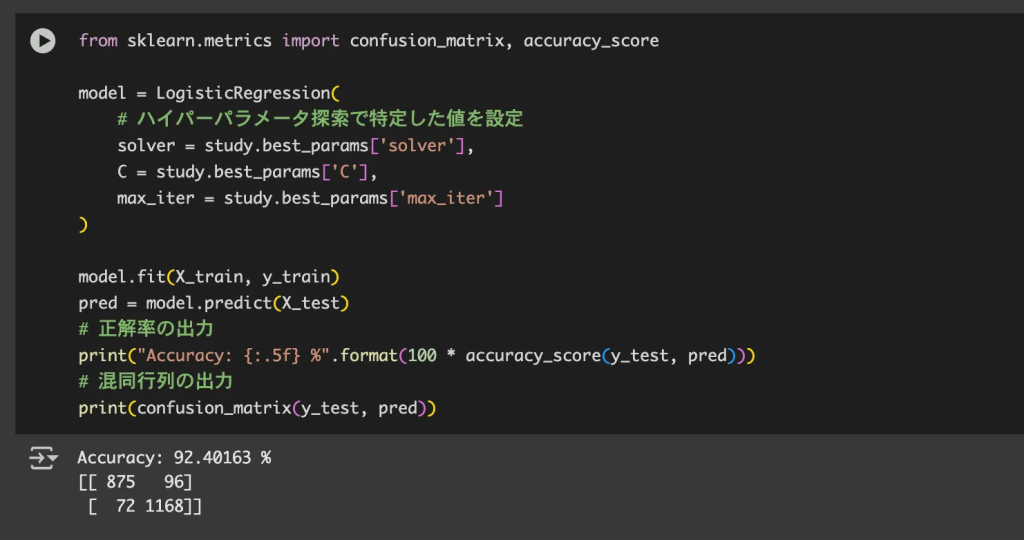
sklearnのロジスティック回帰と決定木モジュールを用いて、UCI Machine Learning Repositoryのデータセットで迷惑メールの検出を行います。これらはどちらも基本的な分類アルゴリズムですが、得意不得意があり、使い分けが重要となってきます。
| 観点 | 決定木(Decision Tree) | ロジスティック回帰 (Logistic Regression) |
|---|---|---|
| モデルのタイプ | 非線形・木構造 | 線形モデル |
| 予測の仕組み | 条件分岐(if-then)による分類 | 特徴量の線形結合+シグモイド関数で確率を算出 |
| 可視化 | 木の形で視覚的に理解しやすい | 回帰係数を数式で把握する |
| 特徴量の扱い | カテゴリ・数値ともに柔軟に対応 | 数値的な特徴量が向いてる(要ワンホット) |
| 前処理の必要性 | 基本的になし | スケーリングやダミー変数化が必要なことも |
| 過学習しやすさ | 高(特に深い木) | 中(正則化で抑制可能) |
| パフォーマンス | 単体では弱いが、ランダムフォレスト等で強化可 | 単体で高速・安定した性能 |
sklearnではそれぞれ以下のモジュールのクラスで容易に実装できます
from sklearn.linear_model import LogisticRegression # ロジスティック回帰
from sklearn.tree import DecisionTreeClassifier # 決定木

X = training_data[:,:-1]
y = training_data[:, -1]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, shuffle=True, random_state=101)
このコードでデータセットを訓練用とテスト用に分割します。テスト用にはデータセットの20%を割り当て過学習を防ぎます。
以下のようなコードで処理を進めていきます。
コードの詳細については本書を参考にしてください。
ハイパーパラメータのチューニング
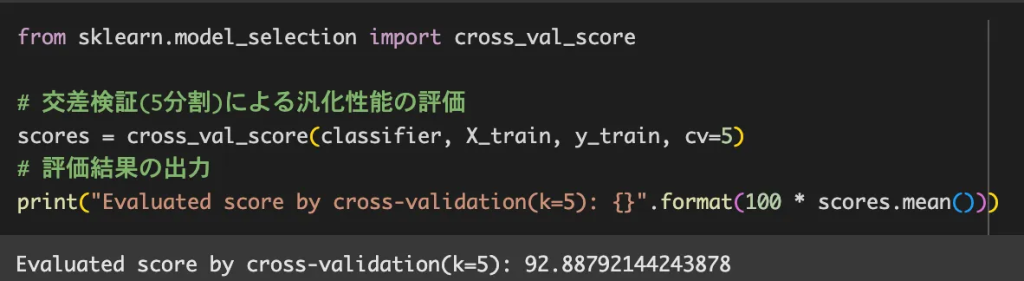
ハイパーパラメータのチューニングとは、機械学習モデルの「設定値」を調整して、モデルの性能(精度や汎化性能)を最大化する作業のことです。先ほど紹介したoptunaを用います。
チューニングが必要な理由:
ハイパーパラメータの設定によって、モデルの性能は大きく左右されます。 正則化が強すぎる場合、過学習の防止にはなるものの、学習が不十分になり精度が低下します。
逆に正則化が弱すぎる場合、訓練データに過剰に適合し、汎化※5性能が落ちてしまうこともあります。

※5 簡単に言えば、「未知のデータに対しても正しく予測できる能力」のことを指します。
迷惑メールの検出器の開発(勾配ブースティング・NLP)
迷惑メールの検出器の開発にあたっては、機械学習・ディープラーニングのアルゴリズムの他に、自然言語を実際に処理して分析する技術が必要になります。この自然言語を扱うための技術をNLP(Natural Language Processing)といいます。
NLP(自然言語処理)の手順(30頁 図2-8より)
字句解析
テキストを単語や形態素に分割し、品詞を特定する
↓
構文解析文法構造(係り受け、句の関係)を解析する
「セキュリティエンジニアのための機械学習」より
↓
意味解析
単語や文の意味を理解し、曖昧さを解消する
↓
談話統合
複数の文をつなげて前後関係や指示語などを解釈する
↓
語用論的分析
文脈・話者の意図・社会的背景などを踏まえて意味を補完する
NLPを行うにあたって、言語情報を特徴量として利用できるようにするためにtf-idfを使用します。tf-idfとは、文書内での単語の出現頻度と、他の文書群における出現頻度の逆数を組み合わせることで、その単語の相対的な重要度を算出する指標です。下記に簡略化した定義を載せます。
TF-IDF(t, d) = TF(t, d) × IDF(t)
- TF(t, d) = 単語 t の文書 d における出現回数(または割合)
- IDF(t) = log( N / (df(t) + 1) ) + 1
- N:全体の文書数
- df(t):単語 t を含む文書の数
このように、その文書でよく使われて、他の文書ではあまり使われていない単語ほど、TF-IDFスコアが高くなり、その文書の“特徴的な語”として扱われます。
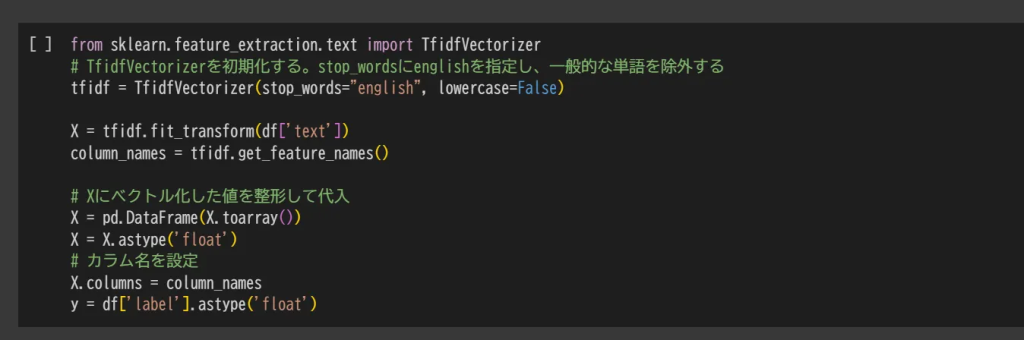
本書では、この計算を sklearn.feature_extraction.text モジュールの TfidfVectorizer クラスを用いて行います。
PandasのDataFrameオブジェクトに迷惑メールリストを変換します。それをTfidfVectorizerでベクトル化します。
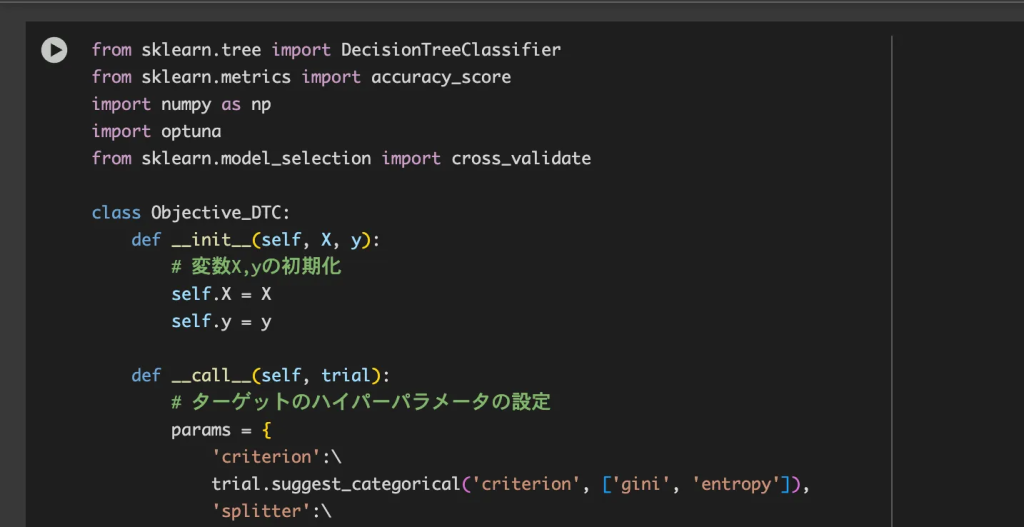
今回はLightGBMというマイクロソフトによって公開された勾配ブースティング木※6というアルゴリズムを用います。このアルゴリズムについて詳しくは第3章で記載されています。今回もハイパーパラメータのチューニングをoptunaで行ってます。
※6 勾配ブースティング木(Gradient Boosting Decision Trees)は、たくさんの「決定木(Decision Tree)」を組み合わせて、高精度な予測を行う手法です。1本1本の木はそこまで賢くないけれど、「間違いを少しずつ直していく」ことを何度もくり返すことで、最終的にかなり正確な予測ができるようになります。
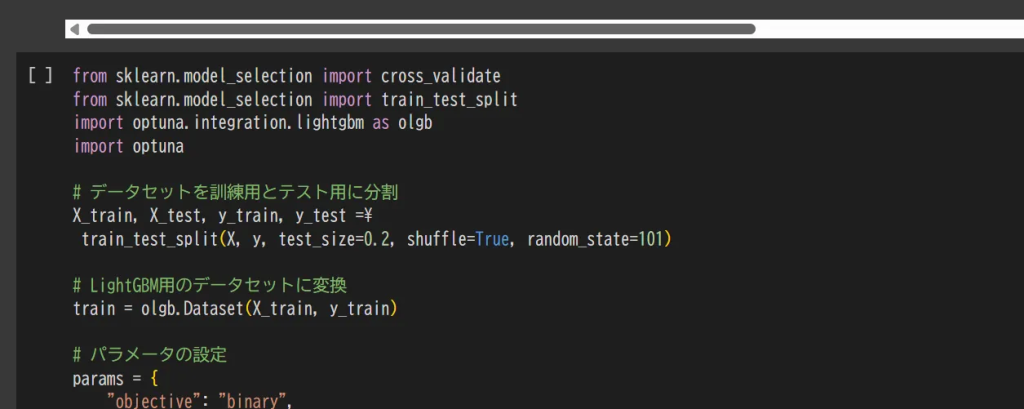
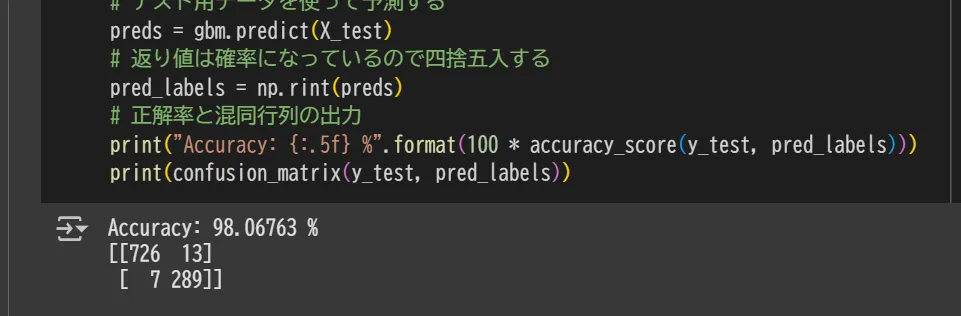
実行結果、この場合、98%の精度で迷惑メールを検出できました。
これで本章は終わりですが、章末には演習問題が載っています。時間に余裕がある方はこれらを解くことで理解が深まります。
第3章 ファイルのメタデータを特徴量にしたマルウェア検出★★★
本章では機械学習アルゴリズムを駆使して、マルウェア検知器を実装しつつ、メモリ解析の手法や、ランダムフォレストなどの機械学習アルゴリズムについて学びます。
マルウェア解析の種類
マルウェア解析にも様々なアプローチがあります。以下のようなものがあります。
- 表層解析
- ウイルス対策ソフトによるスキャン
- ハッシュ値の取得
- 文字列の抽出
- PEヘッダ
- のちのちこれについて詳細に取り扱います
- 動的解析
- マルウェア解析用サンドボックスを用いて、感染動作を記録する手法
- 生成する子プロセスの情報、TCPの通信などがここからわかります。
- メモリ解析
- 感染PCのメモリダンプを分析する手法
- Volatility3などを利用します。
また、マルウェアは検出を回避するために以下のような手段をとります。
検出回避の手段
- 難読化
- ファイル寄生
- パッキング
PEヘッダとは
PE(Portable Executable)は、Windowsで実行ファイルが正しく動作するための構造化フォーマットです。多くのマルウェアはこれを改ざんして検出を回避します。ここにあるインポート、エクスポート、タイムスタンプなどの情報はマルウェア解析にも役立ちます。
PEファイルの基本構造
PEファイル
├── ヘッダ
│ ├── DOSヘッダ
│ ├── PEヘッダ
│ ├── オプショナルヘッダ
│ └── セクションテーブル
└── セクション
├── コード
├── インポート
└── データ
PEヘッダ解析には、PEview、PeStudio、Pythonのpefileといったツールを用いることが可能です。
特徴量エンジニアリング
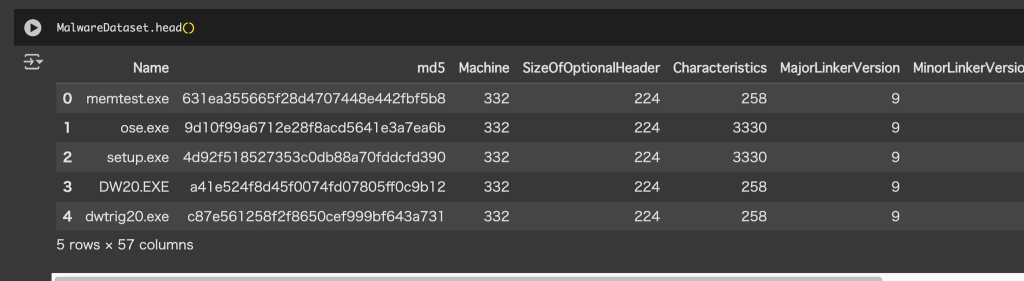
この章ではセキュリティブロガーであるPrateek Lalawniによって配布されたマルウェアのデータセットMalwareData.csvのデータをもとにマルウェア検出を試みます。以下の画像のように、このデータセットでは、各exeファイルのPEヘッダ情報がcsv形式で格納されています。
第一段階として、探索的データ解析(EDA)を行います。探索的データ解析(EDA)とは、データを集計・要約・可視化しながら実際に中身を観察することで、傾向や異常値、特徴を把握する分析の初期ステップです。 探索的データ解析では以下のようなツールが用いられます。
| ツール・ライブラリ | 用途 | 備考 |
|---|---|---|
| pandas | データの集計・要約 | describe() や groupby() などで統計量やグループ集計が可能 |
| matplotlib | 基本的な可視化 | 折れ線、棒グラフ、散布図などの描画に対応 |
| seaborn | 高機能な可視化 | ヒートマップや箱ひげ図など、統計的グラフが得意 |
| plotly | インタラクティブな可視化 | ブラウザ上で操作可能な動的グラフが描画可能 |
| ydata-profiling(旧 pandas-profiling) | 自動EDAレポート生成 | 一行で詳細な統計・可視化レポートを生成 |
| Sweetviz | 可視化中心の自動EDA | 複数データセットの比較に適しており、HTML出力も可能 |
| dtale | GUIベースでEDA操作 | pandasデータフレームをブラウザで直感的に確認・操作可能 |
本書ではpandas-profilingが使用されているのですが、こちらは名前がydata-profilingに変更されています(機能は同じです)。
このツールを使うと、データセットの各カラムについて、値の分布や欠損値の有無、ゼロの割合などを自動で可視化できます。
MalwareData.csvのデータセットにydata-profilingを用いてみました。以下のようなレポートが生成されました。
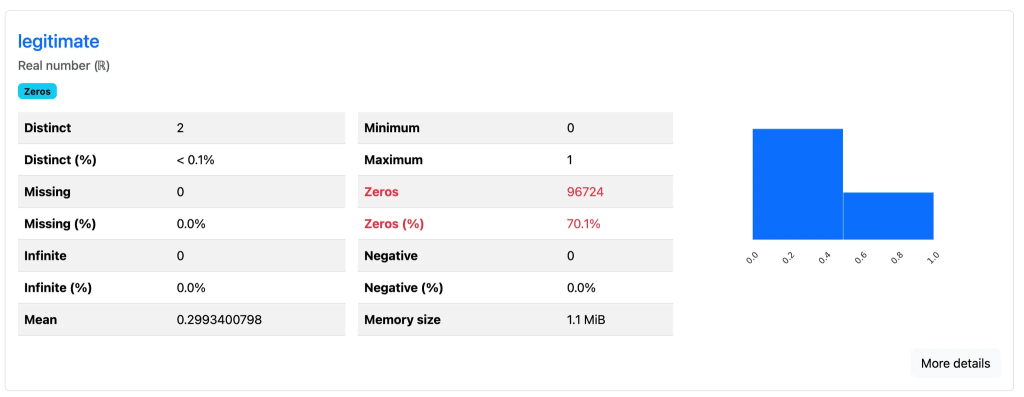
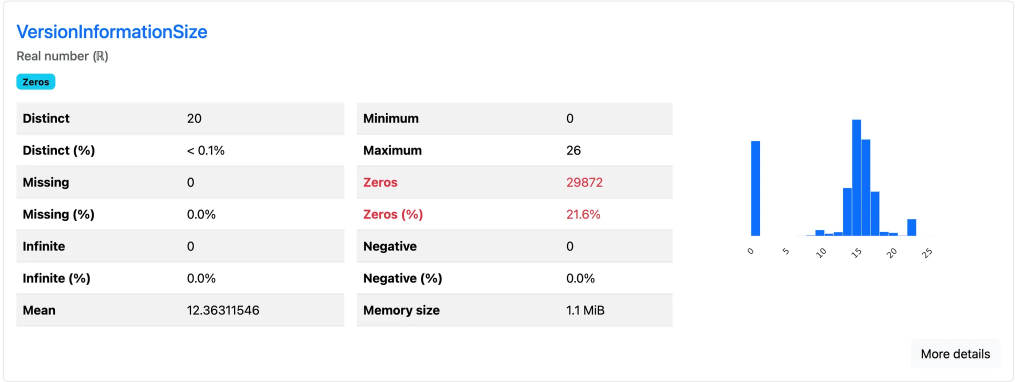
たとえば、MalwareData.csv の「legitimate」列では、値が 0 と 1 の2種類しかなく、そのうち約70%が 0(偽物)であることが一目でわかります(下図の赤い部分)。また、「VersionInformationSize」列では、0〜26までの数値が観測され、ゼロが約21%を占めていることがわかります。
このように、ydata-profiling を使うことで、データの偏りや異常値、欠損の有無などを視覚的に確認でき、前処理やモデリングの方針を立てやすくなります。
今回は、 ydata-profiling によって得られたレポートを眺める中で、「legitimate」と「VersionInformationSize」という2つのパラメータが特に気になりました。そこで、これらの関係を詳しく調べるために、matplotlib を使ってそれぞれの分布を重ねて可視化してみたところ、両者の間に明確な違い(相関関係)があることが視覚的に確認できました。
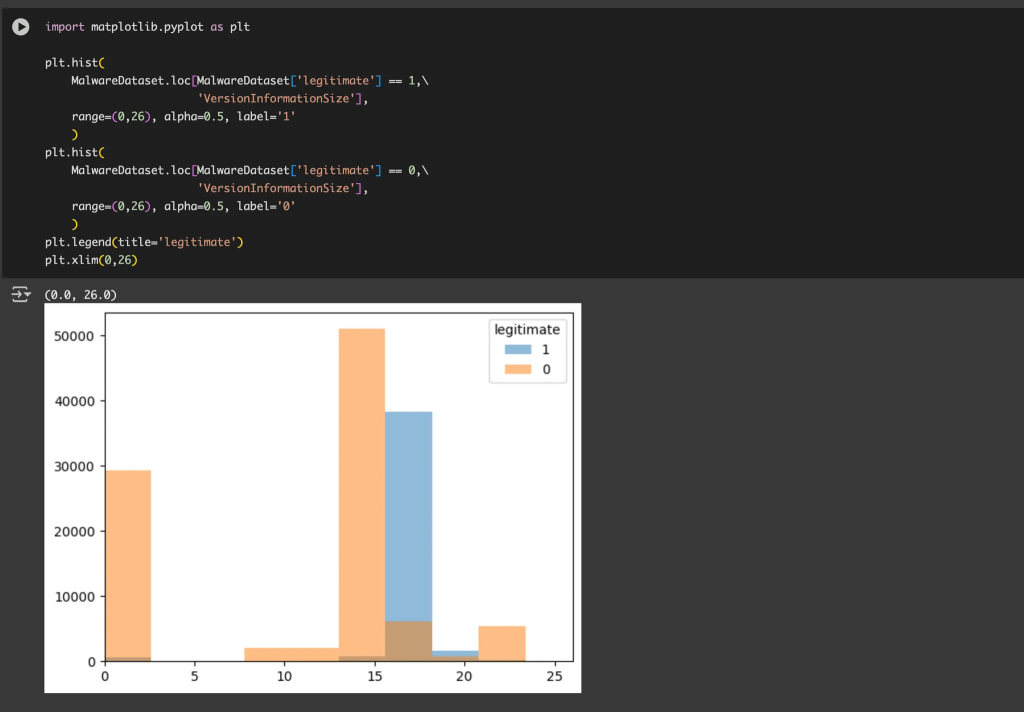
こうやって見つけた関係を元に、手動で新たな特徴量を作り出すこともあります。また、不要な特徴量を削除することもあります。そうすることで機械学習アルゴリズムがよりうまくいきます。
以下に探索的データ解析(EDA)の流れを図にしました。
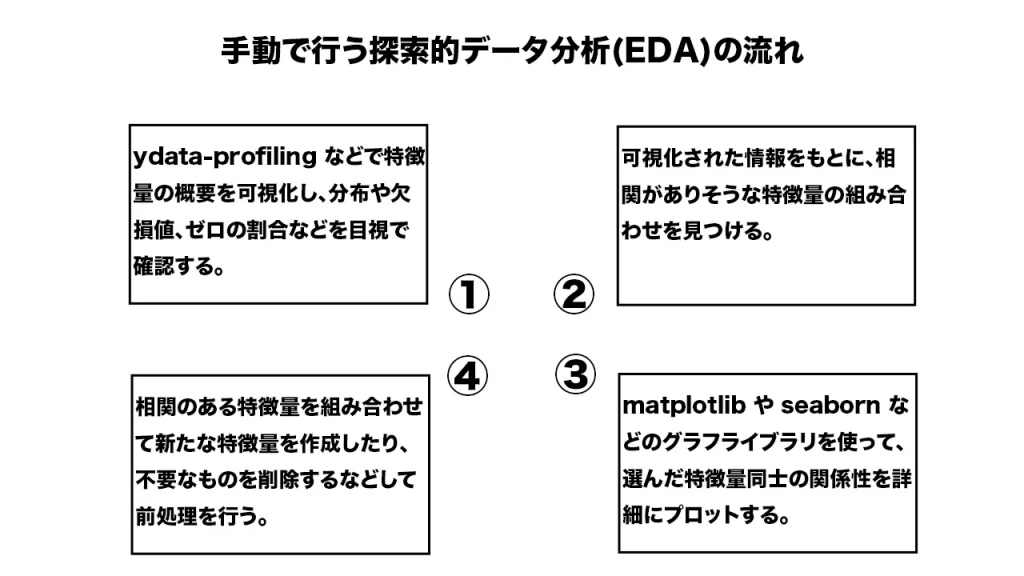
この④の工程が特徴量エンジニアリングです。
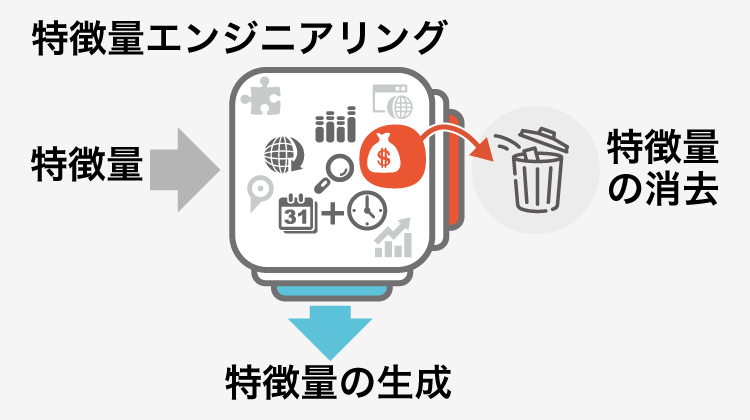
これらを特徴量エンジニアリングといいますが、非常に重要でかつ専門的な工程です。kaggle(データサイエンスの実力を実践で試し、世界中と競い合えるオンライン競技場)などの上級レベルとなると、機械学習アルゴリズムへの知識量よりも特徴量設計が勝敗をわけることが多いです。
機械学習を用いた特徴量の分類
機械学習アルゴリズムを用いて、重要度の高い特徴量を選択することも可能です。本書ではsklearnの以下のライブラリを用いて、分類を行ってます。
ExtarTreesClassifier(複数の決定木を使って分類するアルゴリズム)RandomForestClassifier(ランダムフォレスト)GradientBoostingClassifier(勾配ブースティング)AdaBoostClassifier(AdaBoost)
以下のようなコードでパラメータ設定さえ正しく行えば、それぞれのアルゴリズムを比較的簡単に実装できます。第一段階として、特徴量を機械学習アルゴリズム(この場合ランダムフォレスト)を用いて選択します。
以下にランダムフォレストを用いた場合のコードの様子を示します。

その後、以下の第二段階のコードで得られた特徴量をパラメータに用いて、モデルを学習し、正答率を評価しています。
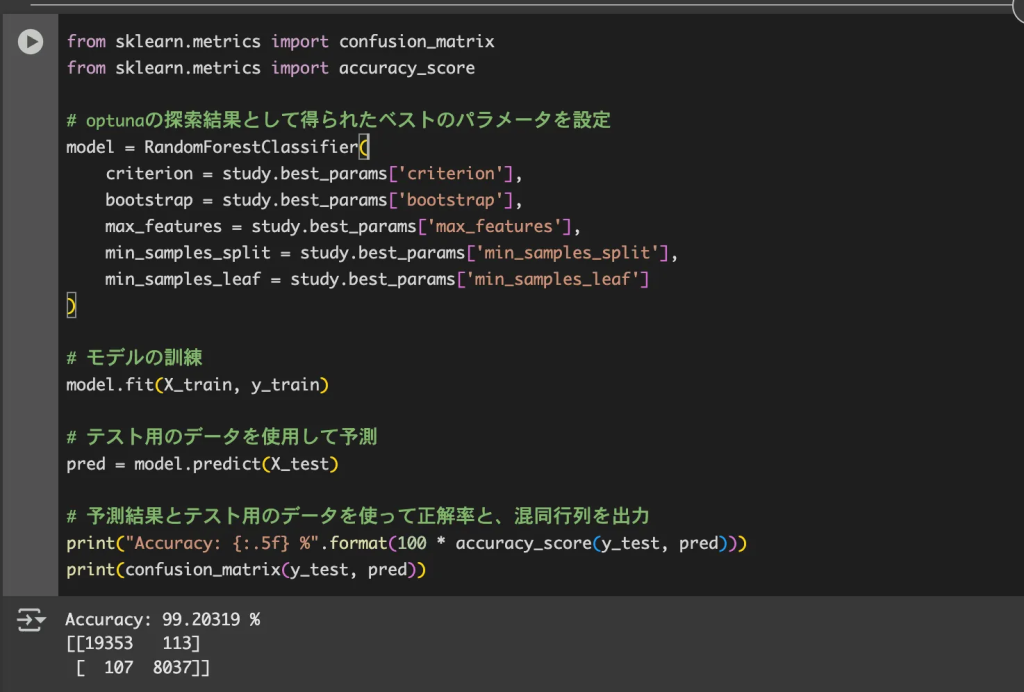
これはつまり、ランダムフォレストアルゴリズムを用いて、選択された特徴量で学習を行った結果、99.2%の確率でマルウェア検出に成功できたということがわかります。
詳しくは本書を読んで欲しいのですが、それぞれのアルゴリズムには得意不得意があり、今回のケースでも正答率に違いが出ています。プロのデータサイエンティストの場合、コストとの兼ね合いも含めて、これらを的確に選ぶ能力が求められます。
本書では次の節でAndroidマルウェアのデータセットを題材にSVM(Support Vector Machine)を用いた例も掲示されてます。
| アルゴリズム名 | 分類 | 主な特徴 | 長所 | 短所 |
|---|---|---|---|---|
| ExtraTreesClassifier | バギング系 | 非常にランダムな決定木を多数構築 | ・学習が高速・過学習しにくい | ・解釈性が低い・ノイズにやや敏感 |
| RandomForestClassifier | バギング系 | ランダムサンプリング+特徴量選択の多数決 | ・過学習に強い・特徴量の重要度が分かる | ・推論が遅くなる・メモリ使用量が多い場合あり |
| GradientBoostingClassifier | ブースティング系 | 弱い学習器を順番に重ねて誤差を補正 | ・非常に高精度・柔軟性が高い(回帰にも使える) | ・学習時間が長い・過学習しやすい |
| AdaBoostClassifier | ブースティング系 | 誤分類に重みをつけて弱学習器を組み合わせ | ・実装がシンプル・ノイズが少ないと高精度 | ・外れ値に弱い・データの前処理が重要 |
| SVM(Support Vector Machine) | マージン最大化 | マージンを最大化する超平面で分類 | ・高次元データに強い・カーネルで非線形も対応可能 | ・データが多いと遅い・ハイパーパラメータの調整が難しい |
3章までで、概要レベルですが古典MLの代表的なアルゴリズムをPythonで実装する方法を学べました。
第3章までを読んで
第3章まででは、ロジスティック回帰・決定木・SVMといった古典的な機械学習アルゴリズムの実装を一通り体験することができました。今後公開予定の「第二回」では、AdaBoostやSVMとは異なるアプローチから発展した、現在のAI技術の主流であるディープラーニングについて取り上げます。加えて、その応用例として、機械学習システムへの攻撃や、ディープラーニングを活用したマルウェア検知器の実例も紹介する予定です。
将来的に機械学習・ディープラーニングエンジニアとして活躍したい方にとって、第3章までの内容は欠かせない基礎となります。本書には優れた演習問題も多数収録されており、これらに積極的に取り組むことを強くおすすめします。







