




第六回の連載では湯本が確立したテスト手法であるIDAU法のテストプロセスを、ソースコードレベルのテストに応用した、Code Based IDAU法(CB-IDAU)について説明しました。第七回では、第5回の記事の中で述べたもう一つの応用研究の仮説の一つである、数学的グラフ特徴量によるバグ予測(Mathematical Graph Feature Metrics Test)の研究について説明したいと思います。(以降、本研究で提案するバグ予測モデルをGMTと表記します。)
GMTの仮説と目的
第五回の記事において記載した、湯本が確立したIDAU法をソースコードレベルのテストに応用したCB-IDAU法を実現するために必要になったデータや結果を応用した、GMTについて、再度、説明します。
IDAU法をソースコードレベルのテストに応用したCB-IDAU法を実現するために、テストのインプットデータとなるソースコードのデータを、一旦、Control Flow Graph (CFG)の数学的なグラフ構造に変換する必要がありました。そして、IDAU法に必要となるCRUDデータも、CFGのグラフノードに属性情報として付与することが必要でした。CB-IDAU法では、このCRUD情報が属性情報として付与された数学的グラフ構造であるCFGを、IDAU法のテスト抽出プロセスに従ってテストケースを抽出するために利用しましたが、他の用途として静的コードバグ予測のためのインプットデータとしての活用が仮説として考えられます。なぜなら、このCFGのデータ構造はソースコードの情報を数学的なグラフ構造としてモデル化されており、数学的グラフ特徴量やCRUD情報を静的コードのメトリクスとして、発生したバグとの相関性を計算することが出来ると考えられるからです。一般的によく知られている静的コードバグ予測のメトリクスとして、LOC、ネスト数、複雑度のようなメトリクスが知られていますが、数学的グラフ特徴量やIDAUで利用したCRUD情報をメトリクスとしてバグ予測が可能ではないかという仮説の元、実際に発生したバグ情報との相関性を計算し、バグ予測モデルを作成することが、GMTの目的なります。
図1にGMTのバグ予測モデル生成のためのプロセスのイメージを示します。

図1 GMTイメージ
仮説実現のための課題と対策
本研究では、既にCB-IDAU法を実装した時点で、ソースコードを中間コードに変換し、CRUD情報を属性情報として付与したCFGを網羅的に生成可能な状況ではあるものの、GMTの目的であるバグ予測モデルを作成するためには、以下の課題があります。
- 課題1. モデル式の定義
バグ予測を行うためには、各メトリクスとバグ情報との相関関係をモデル式として表現する必要があるが、具体的にどのようなモデル式を作成するのか?
- 課題2. 数学的グラフ特徴量の計算
すでに大量のCFGを生成する基盤を確立しているものの、これらの情報から具体的にどのようなアプローチで数学的グラフ特徴量を計算して保持するのか?また、どのような特徴量をバグとの相関を計算するメトリクス候補として採用すべきか?
- 課題3. バグ情報の取得
CFG上の特徴量と実際に発生したバグ情報との相関を調べるために、過去の大量のバグ情報を取得し、相関を計算可能なデータ形式として保持する必要があるが、具体的にどこから、どのような手法でバグ情報を取得し、どのようにデータを表現するべきか?
GMTの研究においては、これらの課題を克服するために以下のような対策を行いました。
- 課題1の対策:重回帰解析とAICの採用
バグ予測のモデル式としては、目的変数としてバグ情報、説明変数としてグラフ特徴量などの各メトリクス値として、離散型二項分布一般化線形モデル(Binomial General Liner Model)を採用しました。また、目的変数であるバグ情報との関連が最も深い説明変数を絞り込むための手法として、統計学の手法の一つである、AIC (Akaike Information Criterion)を用いました。重回帰分析の式は、目的変数Y、説明変数Xiとし、各説明変数の係数をαi 、補正項をβとし、iを1からnまでの整数値でメトリクスの総数を表すとすると以下の式で表現出来ます。
Y = α1X1 + α2X2 +・・・+αnXn +β (式1)
本研究ではそれぞれの変数を以下のように定義し、バグ予測モデル式として用います。
Y : バグ情報
X : 既存の静的コードメトリクス値や数学的グラフ特徴量
α: 各メトリクスや特徴量がどれだけバグに相関しているかの重み係数
後述するバグ情報やメトリクス・特徴量の大量のデータから、代表的な統計解析ツールであるRのライブラリを利用して、重回帰解析とAICの計算を行うことで、最もバグYに相関のあるメトリクス・特徴量Xのセットを抽出し、その重み係数も付与します。
- 課題2の対策:igraphによる数学的グラフ特徴量の計算
CFGから数学的グラフ特徴量を計算するために、本研究ではRの代表的グラフ計算・可視化ライブラリであるigraphを利用しました。下図2にigraphを利用してBonachich Power 中心性の特徴量を計算し可視化したグラフを図示します。このグラフは、連載第五回にも掲載したグラフになります。
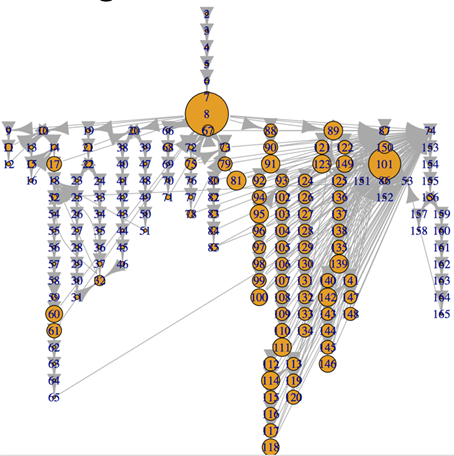
図2 igraphで計算したグラフ特徴量 Bonachich Power中心性の例
続きを読むにはログインが必要です。
ご利用は無料ですので、ぜひご登録ください。










