




本連載では、ブロックチェーンの基本的な仕組みを解説しながら、オンチェーンデータを分析するための基本的な手法について、全8回で紹介します。
第4回となる今回は、オンチェーンデータ分析の手法としてSQLを用いることのメリットについて、SQLの背景にある概念や歴史などを交えながら解説していきます。
データ分析のためのSQL
SQLとは、もともとリレーショナルデータベースと呼ばれるデータベースシステムからデータを抽出したり、データを操作したりするための専用の言語でした。近年では、SQLの完成度と汎用性の高さから、データベース分野に留まらず、広くデータ分析の用途でもSQLが活用されています。
コード1. SQLのサンプルコード
CREATE TABLE sample (
id INT,
name TEXT,
description TEXT
);
INSERT INTO sample VALUES (1, 'AAA', 'some text');
INSERT INTO sample VALUES (2, 'BBB', 'some text');
SELECT id, name
FROM sample
WHERE id <= 1
LIMIT 10;
ここで、単なるデータの集合とデータベースの違いについて補足しておきます。まず、「データ」という言葉の定義自体がさまざま存在しますが、ここでは「一定の形式(フォーマット)で整えられた事実や数値」といった意味で取り扱うこととします。例えば、ある企業に属する従業員のIDや氏名、生年月日などをCSV形式やJSON形式で保存したテキストファイルは、典型的なデータの一種です。
一方、データベースとは、こうしたデータの集合を体系的に構成し、データを簡単に検索したり、整合性を持って更新したりできるようにしたものを指します。無秩序なデータを単に寄せ集めたもので、目的のデータを簡単に抽出したり更新したりできないような状態になっているデータの集まりであれば、一般的にはデータベースとは呼ばれません。
なお、ビッグデータの文脈では、従来のデータベースで管理されているような体系的なデータの集合を「構造化データ」、それ以外の多種多様で雑多なデータ群を「非構造化データ」と呼ばれることもあります※1。ICT技術の発展に伴い、この「非構造化データ」が急速に生成・保存されるようになったことで、ビッグデータの活用という概念が注目を集め始めました。この文脈に即して冒頭の説明を言い換えると、「SQLはもともと『構造化データ』を操作するために利用されていた言語だが、近年では『非構造化データ』に対してもSQLを適用してビッグデータ分析に活用する事例も増加している」とも表現できます。
※1 総務省 平成25年版 情報通信白書 – ビッグデータの概念
3層スキーマ
多くのデータベースシステムでは、物理的に保存されたデータのフォーマットとは別に、抽象的な概念としてのデータモデルを備えています。
米国国家規格協会(ANSI)の標準化計画要求委員会(SPARC)が提唱した「3層スキーマ」というモデルでは、データベースの構造を「外部スキーマ」「概念スキーマ」「内部スキーマ」という3つのスキーマに分けて定義しています。これは、データの物理的な保存形式である「内部スキーマ」と、データを加工して利活用するビューとしての「外部スキーマ」との間に、緩衝材となる抽象的な「概念スキーマ」の層を配置することで、データの独立性を保つための構造です。
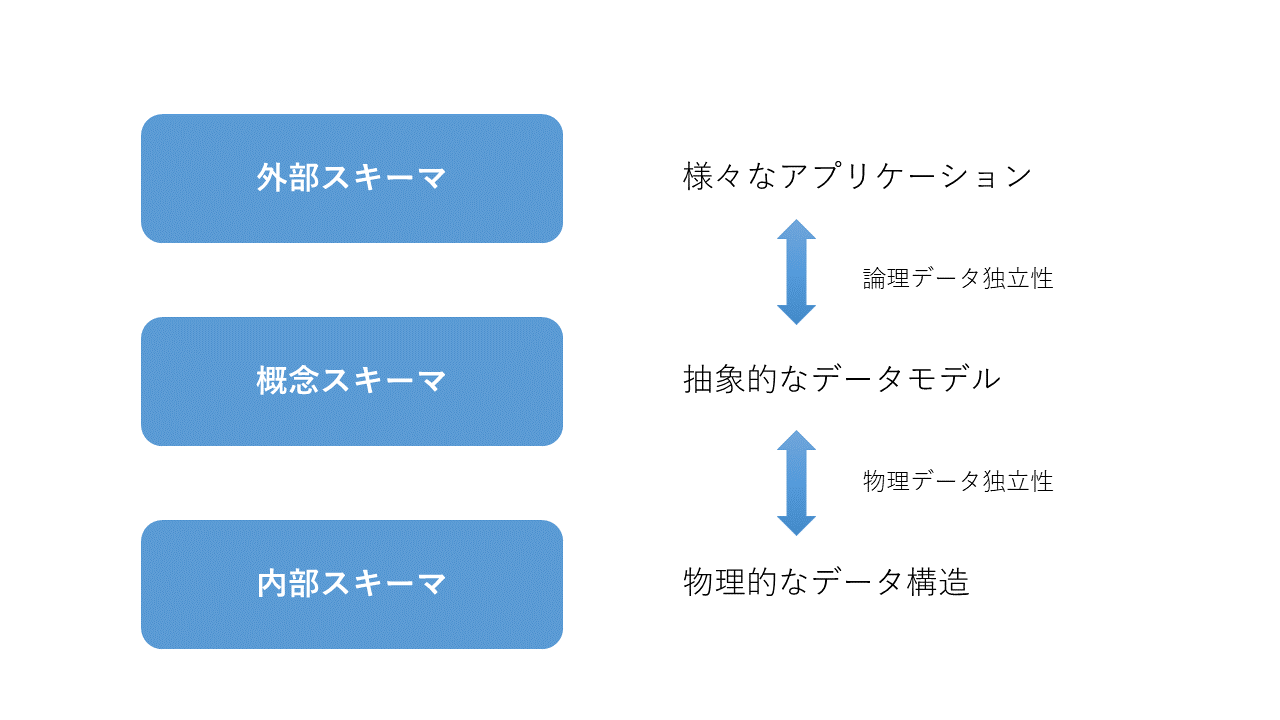
3層スキーマの考え方を用いず、物理的なデータを直接プログラミング言語などで加工してデータ分析する手法も存在します。CSVファイルなどで保存されたデータをPythonなどで読み込み、直接加工するような方法です。
このとき、物理的なデータの格納方法を変えたいときに、同時にプログラム側の改修が必要となったり、逆にデータの表示形式を変えたいときに、物理的なデータの格納方法を変更しなければならなくなったりすることがあります。こうした状態はデータの独立性が存在しない状態と言えます。一人のデータ分析者がデータを取り扱うだけであればそれほど問題はないかもしれませんが、多くの分析者が同時に同じデータを扱ったり、分析者とは異なる人物がデータの保存方法をメンテナンスしていたりする場合には、3層スキーマのような形でデータの独立性を担保してあげたほうが良いでしょう。
こうしたデータの独立性を担保するために、SQLという言語は共通のインターフェースとして非常に都合が良かったため、データベース分野だけでなく、広くデータ分析のために活用されてきています。
リレーショナルモデル
データベースの種類には、オブジェクトデータベースやグラフデータベース、ドキュメントデータベースなど様々なものが存在しますが、SQLとともに広く普及しているデータベースの種類がリレーショナルデータベース(RDB)です。
続きを読むにはログインが必要です。
ご利用は無料ですので、ぜひご登録ください。







