この記事は2023年9月26日(火)に開催されたプレミアムセミナー登壇を記念してDr. Stuart Reidによって執筆されました。
プレミアムセミナーの詳細はこちらをご覧ください :
■9.26開催!Stuart Reid博士 特別セミナー|知識ゼロから学ぶAIテスト

オリジナル英語版はこちらに掲載しています。
■Risk-Based Testing for AI (English version/オリジナル英語版)
はじめに
リスクベースドテスト(RBT)は、1990年代初頭から様々な形で存在し、過去25年間、主流のアプローチとして受け入れられてきました。これは、ISO/IEC/IEEE 29119シリーズのソフトウェアテスト標準の基礎であり、すべてのテストはリスクベースであるべきと義務付けています。RBTはまた、ISTQBのようなテスター認定制度にも不可欠な要素であり、全世界で100万人を超えるテスターがRBTアプローチを教わっていることになります。
AIの歴史はRBTよりも古いですが、主流技術となり、多くの人が利用するようになったのはここ数年のことです。研究室での使用から日常的な使用、時には重要な分野での使用への進化は、商業的なAIシステムを体系的にテストする必要があるという認識が高まっていることを意味しています。AIシステムに対する社会的信頼の欠如は、これらのシステムのテストに対するより専門的なアプローチの必要性を強めています。
一部のデータサイエンティストによれば、AIは従来のソフトウェアとは大きく異なるため、誰がどのようにテストするのかを含め、これらのシステムを開発するための新しいアプローチが必要です。
この記事では、RBTの基本概念を紹介し、その適応可能な性質を示し、機械学習システム(MLS)のテストにRBTをどのように使用できるか、また使用すべきかを示します。また、MLSに特有なリスクの多くを列挙し、これらを通して、これらのリスクに対処するために必要な、いくつかの新しいテストタイプと技法を特定します。最後に、これらの新しいテストタイプや技法だけでなく、これらのシステムの基盤となるAI技術を理解する専門テスターの必要性を説明します。
リスクとITシステム
私たちは日常生活の中で毎日リスクを取り扱っています(例えば、「横断歩道まで50メートル余計に歩くべきか、それとも時間を節約してここを渡るべきか」など)。同様に、多くのビジネスもリスクの管理に基づいており、おそらく金融や保険に携わる人々が最も顕著でしょう。
ITシステムの開発やテストに携わる人々にとって、リスクベースのアプローチの使用は、そのようなシステムの信頼を確保する手段として、長い間受け入れられてきました。その中には40年近く前のものもあり、安全関連とビジネスクリティカルの両方に多くの業界固有の標準が存在し、ソフトウェア開発とテストの両方についてリスクに基づく要件を定義しています。
なぜリスクベースのテストなのか?
リスクベースのテストには、以下のような利点があります:
より効率的なテスト リスクベースのテストを使用する場合、テスト対象のシステムのうち、よりリスクの高い部分を特定し、その部分に対するテスト工数の割合を高くします。同様に、リスクの低い部分については、テスト工数を少なくします。この結果、一般的にテストリソースをより効率的に使うことができ、システムが納品された後に問題となる高スコアのリスクは少なくなります。RBTのこの側面は、単純に使用するテスト工数を調整するという形を取ることもできますが、特定のリスク領域に対処するために、専門的なテストタイプを使用することも含まれます(例えば、ユーザーインターフェースのリスクがある場合、そのリスクに対処するために、専門的なユーザビリティテストを実施することを決定するかもしれません)。
テストの優先順位付け どのテストが最も高いリスクと関連しているかがわかれば、それらのテストを早めに実行するようスケジューリングできます。これには主に2つの利点があります。第一に、万が一テストが途中で打ち切られるようなことがあっても、最もリスクの高い領域にはすでに対処済みであることがわかります。第二に、リスクの高い領域で問題が見つかった場合、それに対処するための時間が残されていることを意味します。
リスクベースのレポーティングとリリース リスクベースのアプローチを使うことで、いつでも、未解決のリスク(つまり、テストや処理が済んでいないリスク)の観点から、システムの現状を簡単に報告することができます。これにより、プロジェクトマネージャーと顧客に対して、今システムをリリースすることを決定した場合、まだテストしていないリスクはすべて存在することを助言することができます。(つまり、そのリスクとともにシステムを受け入れることになる)
このように、システムをリリースするかどうかの決定は、彼らがその存在を知り、同意したリスクに基づいて行うことができるのです。
RBTプロセス
リスクベースのテストは、典型的なリスク管理プロセスに従います。その簡略化されたバージョンを図1に示します。
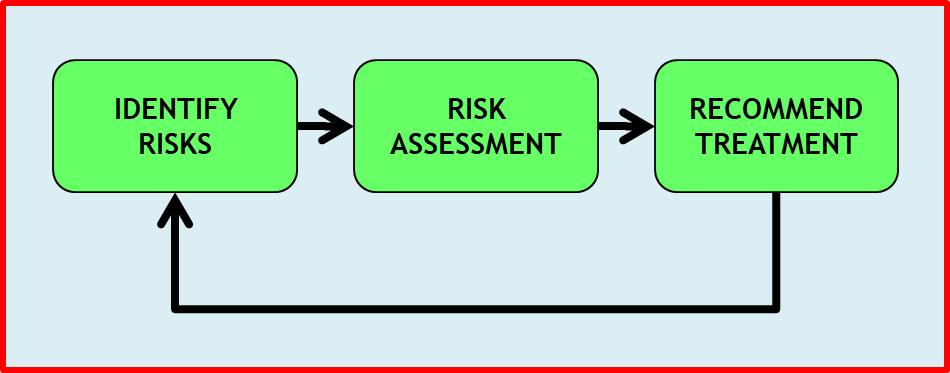
まず、該当するリスクを特定します。次に、これらのリスクを評価し、相対的な重要性を見積もります。そして、どのリスクをテストで処理できるかを決定します。しかし、リスク管理は一回で終わることはほとんどなく、通常は変化するリスクに対応する継続的なプロセスになります。
リスク識別
RBTは、プロジェクトリスクとプロダクトリスクという2種類のリスクの識別と管理に関するものです。
プロジェクトリスクは、プロジェクトマネージャーが使用するリスクと同じ種類のものです(多くの場合、プロジェクトリスク登録簿に文書化されます)。プロジェクトリスクは、主に納期と予算内に納品できるかどうかに関係します。プロジェクトリスクはまた、適切なスキルを持ったテスターの利用可能性や、開発者からテスターへのコードの納期遵守の可能性にも関係します。
テストマネージャーとして、プロジェクトリスクは、テスト計画に含めるテストの種類と量に大きな影響を与えます。例えば、新しいテスト技法を使用する場合、テストチームに必要な実装スキルの欠如や、テストツールのコスト増加のリスクが発生する可能性があります。
プロダクトリスクは、テストに特化したものです。これらは、成果物に関連するリスクであり、エンドユーザに影響を与えるリスクです。高いレベルでは、プロダクトリスクを機能的品質属性と非機能的品質属性の観点から考えることができます。例えると、機能的なプロダクトリスクは、車の窓を制御するソフトウェアが、閉まる窓が子供の頭にぶつかったときに適切に反応しないことです。非機能的なプロダクトリスクは、車載情報娯楽システム(IVI)のユーザーインターフェースが明るい日差しの下で読みにくいこと(おそらく、コントラストと明るさの管理が不十分なため)、ドライバーが新しい機能を選択したときの応答時間が遅すぎるといったことが考えられます。
リスク識別をしようとする場合、理想的には多種多様な利害関係者を巻き込む必要があります。なぜなら、利害関係者によって知っているリスクは異なりますし、可能な限り多くの潜在的なリスクを見つけたいからです(重要なリスクを見逃すと、システムの対応する部分を十分に深くテストできなくなる可能性が高いため、その部分の欠陥が見逃される可能性が高くなります)。
要件は常にプロダクトリスクの重要な源泉として考慮されるべきです。要求された機能が提供されないことは明らかなリスクであり、顧客が受け入れ可能とは考えにくいリスクです(そのため、この種類のリスクの影響が大きくなります)。
■なぜ要件ベースのテストではないのか?
以前は、テストは要件ベースのアプローチに従って行われ、顧客から明示的に要求された要素だけを対象としていました。
しかし、顧客が要件を完璧に記述していない典型的な状況ではどうなるでしょうか?例えば、必要な機能をすべて文書化していなかったり、レスポンスタイム、セキュリティ要件、ユーザビリティのレベルなど、関連する品質属性をすべて明記していなかったりする場合です。単純な答えは、要求ベースのテストでは、このような欠落した要件をカバーできないため、顧客が望むシステムの部分的なテストカバレッジしか提供できません。
また、顧客の要求がすべて同じように重要でない場合(通常の状態)はどうなるのでしょうか。要件ベースのテストでは、すべての要件が同じように扱われます。したがって、自動運転車では、歩行者回避サブシステムが車載情報娯楽システム(IVI)と同じ厳密さでテストされることになります。幸いなことに、安全関連システムについては、要求ベースのテストだけではありません。このようなシステムに関する業界固有の規格では、完全性レベルを用いたリスクベースのアプローチを採用しなければならないと定めています。しかし、どのようなシステムであっても、すべての要件を等しく重要なものとして扱うと、利用可能なテストリソースを非効率的に使うことになります。
では、要件ベースのテストが非効率的で、テストカバレッジの低さにつながるのであれば、代替手段は何でしょうか。リスクベースのテストでは、すべてのシステムに明示されていない要件が存在することを受け入れるため、欠落した要件は、対処すべき既知のリスクとして扱われます。要件の欠落や乏しさが、十分に高いリスクであると認識される場合、テスターは通常、ユーザーや顧客と話をして、このリスクを処理するためのニーズについてさらに詳細を引き出します。テスターは、完全な要件が入手できない場合に有効的とされる探索的テストのような、特定のテストアプローチを選択することもできます。リスク評価(リスクアセスメント)
リスクに割り当てられるスコアは、リスクが発生する可能性と、そのリスクが問題となった場合に与える影響の組み合わせを考慮して評価されます。理想的な世界では、各リスクの大きさを正確に測定できるでしょう。例えば、リスク発生の可能性が50%で、潜在的な損失が10万ドルであれば、そのリスクを5万ドルと評価します(リスクスコアは通常、影響度と発生確率の積として計算される)。しかし、実際にはそれほど単純ではありません。
特定のリスクが問題になった場合、どのような影響があるのか、事業者から正確に教えてもらえることはほとんどありません。例えば、車載情報娯楽システム(IVI)のユーザーインターフェースに関するリスクを考えてみましょう。
旧バージョンのフィードバックから、ドライバーがユーザーインターフェースを使いにくいと感じていることがわかりました。しかし、ビジネスへの影響はどうでしょうか?これは、振り返ってみても測定が非常に困難な場合があります。しかし、自動車が市場に出る前にそれを予測することは、事実上不可能です。
リスクが問題になる確率を計算することは、しばしば簡単な仕事だと考えられています。通常、開発者や設計者(私たちテスターは、通常、より身近な存在である)から、そしておそらくは過去の欠陥データから、これを決定するために必要な情報を得るからです。しかし、特定の領域における故障の可能性を推定することは、厳密な科学ではありません。設計者と話し、リスクに関連するシステムの部分が複雑かどうか、彼らの意見を聞くかもしれません。開発者に話を聞き、彼らが故障の可能性をどのように評価しているかを聞くかもしれません。それは、彼らが不慣れな開発技術やプログラミング言語を使用しているかどうかにもよるでしょうし、設計者や開発者の能力を推定することもできます。しかし、システムのソフトウェア部分が故障する正確な確率を導き出すことはできないでしょう(ハードウェアの方が予測しやすい)。
では、RBTを行う際にリスクスコアを正確に評価できないとしたら、どうすればいいのか。まず、リスクを絶対評価しないことです。その代わり、リスクを相対的に評価し、どのリスクをより厳格にテストし、どのリスクをより緩和してテストするかを決定します。私たちは情報に基づいた推測を行います。これは非科学的に聞こえますが、実際には、リスクスコア間の差は非常に大きいので、情報に基づいた推測で十分なのです。
RBTのリスク評価で最も一般的なアプローチは、高、中、低(影響、可能性、結果としてのリスクスコア)を使用することです。図2は、これがどのように機能するかを示しています。事業者は、あるリスクに対して、低、中、高の影響を提供し、開発者は、低、中、高の故障の可能性を提供します。これらは図2のように組み合わされ、その結果、グラフ上の位置が相対的なリスクスコアとなります。実際の数値をリスクスコアとして割り当てる場合(単にグラフ上の位置から「高」、「中」、「低」のリスクスコアを読み取るのではなく)、これらの数値は、異なるリスクに対する相対的な露出を決定するためにのみ有用となります。例えば、2つのリスクがあったとして、1つは「低-低」で公称スコアが1、もう1つは「高-高」で公称スコアが9であったとしても、2つ目のリスクに1つ目のリスクの9倍の労力を割くことはしません。その代わり、2番目のリスクは1番目のリスクよりも相対的に高いので、より多くのテストを割り当てるべきであることを、スコアは教えてくれるはずです。これが正しいことを確信する必要があるのなら、同じ2つのリスクに対して、影響度と可能性を異なる尺度(例:1~3、1~5)で、同様のアプローチを適用してみるとよいでしょう。
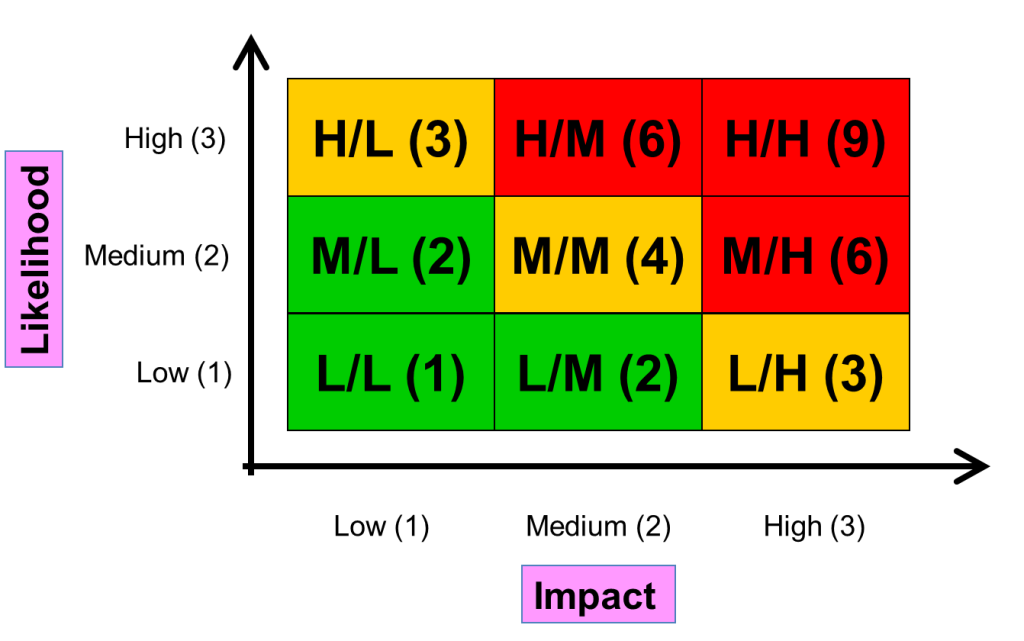
ここまではシンプルでした。以下は、この方法を使う場合の提案です。可能性と影響のスコアを与える利害関係者は、(低いものから高いものまで)全範囲を使用するようにしてください。利害関係者(特にユーザー)の中には、システムの「自分の」部分が最も重要な部分であると考え、常に自分の領域内のすべてのリスクを高インパクトとして採点する人がいることに気づくでしょう。なぜなら、私たちは相対的なスコアを得ることで、リスク間の差別化を図ろうとしているのであり、ほとんどのリスクが高スコアであれば、リスク間の差別化はできないからです。
また、利害関係者がリスクスコアを承認するようにしてください。リリース後にバグが発見されたとき、顧客から「このバグは『ハイリスク』な領域にあったのだから、あなたが発見すべきだった」と文句を言われると、非常にフラストレーションが溜まります。しかし、あなたは、その領域を低リスクとみなすことに合意し、その結果、他のいくつかの領域で実施したテストよりも比較的少ないテストになったことを明確に思い出すことができます。
最後に、リスクスコアの算出によく使う3つ目のパラメータがあります。それは使用頻度です。リスクアセスメントを実施しているときに、2つのシステム機能が共に高リスクに割り当てられたとします。しかし、1つ目の機能は1日に1回しか使用されないのに対し、2つ目の機能は1分に1回使用されるとします。もしその機能が故障した場合、潜在的な故障コストははるかに高くなることがわかります。
リスク対策
RBTプロセスの第3段階はリスク対策です。この時点では、通常いくつかの選択肢があります。例えば、ある低スコアのリスクについて、そのリスクが問題になった場合のコストと比較すると、テストのコストが高すぎると判断する場合があります。低スコアのリスクについてはこのようなケースがよくあり、閾値となるリスクスコアを設定し、このレベルを下回るリスクについてテストを行わないのはよくあることです。あるリスクに対するテストコストが非常に高いことがわかり(例えば、専門的なテスターやツールが必要な場合)、リスクスコアが比較的高くても、そのリスクをテストするのは費用対効果が悪いと判断することもあります。このような場合、私たちは通常、そのリスクを別の方法で扱おうとします。例えば、障害に対処するための冗長性を導入することで、リスクを軽減するよう開発者に求めたり、その機能をシステム内で使用しないようにユーザーに推奨したりします。
テストによってリスクを扱うとき、私たちは関連するリスクスコアを下げるためにテストを使っています。テストがパスすれば、故障の可能性が減少したと結論づけられます(影響は通常変わらない)。テストは故障の可能性がゼロであることを保証できない(欠陥が残らないことを保証できない)ので、通常、この方法でリスクを完全に取り除くことはできません。しかし、ある機能をテストし、テストがパスした場合、そのテスト環境でのテスト入力のセットに対して、その機能は動作し、リスクは問題にならなかったことがわかります。これにより、この機能に対する信頼が高まり、もしリスクを再評価するのであれば、故障の可能性を低く設定することになるでしょう。そうでなければ、リスクスコアを閾値以下にするために、信頼度が十分に高くなるまで(そして故障の可能性が十分に低くなるまで)、さらにテストを実施します。
テストによるリスク対策にはいくつかの形態があり、リスクタイプとリスクスコアの両方に基づいています。高いレベルでは、テスト戦略に何を含めるかを決めることによって、リスクを扱うことが多いです。例えば、プロジェクトでどのテストレベルを使うかを決めたり(例えば、統合が高リスクと考えられる場合、統合テストを実施する)、システムの異なる部分にどのテストタイプを使うかを決めたりします(例えば、ユーザインタフェースに関連する高スコアのリスクがある場合、ユーザビリティテストをテスト戦略の一部に含める可能性が高くなる)。また、リスクは、どのテスト技法とテスト完了基準を選択するかを決定するために使用することができ、テストツールとテスト環境の選択も、評価されたリスクに影響されることがあります。
もっと低いレベルでは、評価されたリスクと、システムとそのユーザーに関する知識の両方に基づいて、一つの機能に対して、どのようにテストを配分するかを(個々のテスト担当者として)決めることがあります。例えば、ある機能をテストしていて、その機能のある部分が他の部分よりも頻繁に使用されることがわかっている場合、(他のすべての条件が同じであれば)使用頻度の高い部分のテストにより多くの時間を費やすことは合理的でしょう。
良いリスク対策は、テスター(とテストマネージャー)のスキルと経験に大きく依存します。もし私たちが2つのテスト技法しか知らないとしたら、4つの可能な選択肢があります(技法Aを使う、技法Bを使う、両方の技法を使う、あるいはどちらも使わない)。しかし、もし私たちが知っている技法のどちらも、認知されたリスクを処理するのに適していない場合、リスクベースのテストの有効性は著しく制限されることになります。一方、テストタイプや技法について幅広い知識があれば、適切な対策を選択できる可能性がはるかに高くなるのです。
RBTは単発の活動であってはならない
多くのプロジェクトでは、リスクベースのテストは、テスト計画とそれに関連するテスト戦略を作成するためのプロジェクト開始時のみに使用され、その後は何も変わらない、限定的な単発の活動として実施されています。しかし、図1の簡略化されたリスクマネジメントプロセスで、「リスクを識別する」に戻る矢印が示すように、RBTは継続的な活動として、理想的にはシステムを廃止するまで継続すべきです。
前述したように、テストが合格し始めると、私たちの自信は増し、故障の可能性は減少するはずです。従って、テストを実行するにつれて、リスクレベルは変化し、それを反映するようにテストも変化するはずです。しかし、テストが失敗した場合など、その逆のケースもあります。この場合、(これらのテスト入力の)失敗確率は100%になり、リスクではなく対処が必要な問題となります(リスクの失敗確率は100%未満でなければならず、そうでない場合は問題となります)。
テストの原則のひとつに、欠陥は集まって発生するというものがあります。したがって、欠陥を発見したときには、欠陥群の一部を発見した可能性を直ちに考慮すべきです。新しく発見した欠陥に近いシステム部分は、故障の可能性が高くなります。そのため、関連するリスクスコアが高くなり、この部分のテストがより多く考慮されることになります。
リスクが変わるのは、テストのせいだけではありません。顧客は、プロジェクトの途中で要求を変更することがよくあり、その場合、即座にリスクの状況が変わります。また、競合システムのリリースのような外的要因によって、あるリスクのビジネスインパクトが変化することもあります(独自の機能がより重要になるかもしれない)。競合システムのリリースが間近に迫っているため、他のシステムより先にリリースできるように、納期(とテスト時間)が短縮され、プロジェクトのリスクが増大することもあります。同様に、予期せぬ冬のインフルエンザの流行も、テスターの可用性と、テスターが提供するテストの能力に関連するプロジェクトリスクを変化させる可能性があります。
RBTとAIシステム
では、AIシステムをテストすることで何かが変わるのでしょうか?一言で言えば、答えは「ノー」です。テストの際、RBTは、AIコンポーネントを含むかどうかにかかわらず、すべてのシステムに適用することができ、また適用すべきです。しかし、AIシステムのテストは、従来の非AIシステムとは異なります。
AIシステムには多くの種類(機械学習システム(MLS)、論理ベースおよび知識ベースシステム、統計的アプローチに基づくシステムなど)があり、それぞれに特有のリスクがあるため、AIシステムの種類ごとにテスト方法が異なります。現時点では、機械学習システムが最も一般的なAIの形態です。次にRBTを使用してMLSをテストする方法を見ていきます。
機械学習システムに伴うリスク
MLSのリスクを明確に分類する方法はありませんが、MLSの開発とMLS自体の両方に関連するリスクがあります。MLSは他のシステムとは異なり、MLSの核となるモデルは、トレーニングデータのパターンを使用したアルゴリズムによって生成されます。図3に、MLSの作成と運用の概略を示します。
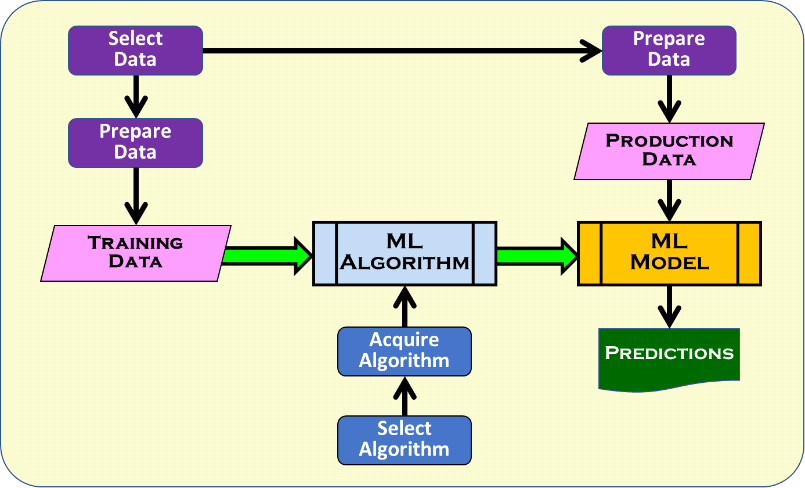
従来の非MLSシステムとは対照的に、MLモデルと呼ばれるMLSコンポーネントは、人がプログラムするのではなく、機械学習アルゴリズムによって生成されます。この再利用可能なアルゴリズム(人によってプログラムされる)は、データサイエンティストによってトレーニングデータが与えられ、このデータのパターンを使用してモデルを生成します。一度導入されると、モデルは類似した実世界の運用データを予測に変換し、例えば画像が猫か犬かを分類します。MLS開発のユニークな性質を考慮し、データサイエンティストはMLモデルの開発に専門的なフレームワークを使用します。
この説明を使って、機械学習を3つの主要分野に分け、機械学習に関連するリスクをこれらの分野の観点から分類することができます:
- 入力データ – 機械学習をサポートするためのトレーニングデータの提供と、運用環境でモデルが使用する本番データの提供に関連する。
- モデル – 生成されたMLモデルに関連する。
- 開発 – MLアルゴリズム、モデルの開発、ML開発フレームワークに関連する。
入力データのリスク
MLSの顕著な特徴の一つは、機械学習プロセスにおけるデータの重要性に起因します。モデルの学習に使用されるデータに欠陥があれば、結果として得られるモデルにも欠陥が生じます。例えば、一部のMLSが一部のマイノリティグループに偏っていることが判明した、という話を聞いたことがある人も多いでしょう。一般的に、この偏りは機械学習のプロセスやアルゴリズムによるものではなく(その可能性もありますが)、トレーニングデータの偏りによるものです。従って、MLSを構築する際、データサイエンティストはシステムの学習に使用するデータに偏りがあるリスクを考慮する必要があります。多くの場合、本質的にバイアスのかかった過去のデータ(例えば、50年前の人種や性別に関する見解を含む)を使用することが原因でバイアスがかかっています。RBTの観点からは、もし偏ったトレーニングデータがMLSにとって潜在的なリスクであることが分かっているのであれば、このリスクに対処するためにテストをどのように利用できるかを検討すべきです。そして、驚くことに、MLSにおけるバイアスのテストは、すでにかなりよく理解されています。
バイアスは、MLSのトレーニングに使用されるトレーニングデータに関連するいくつかの潜在的なリスクの一つに過ぎません。MLS用のトレーニングデータ(および運用データ)の作成は、データサイエンティストの労力を最も多く費やす複雑な作業であるため、うまくいかない可能性(およびそれに対応するリスク)も多く存在しています。以下のリストには、MLSの入力データに関連する最も一般的なリスクをいくつか挙げています:
- 偏ったトレーニングデータ
- 誤ったデータ取得
- 信頼できない情報源からのデータ
- 安全でないデータ入力チャンネル
- 非効果的なデータガバナンス
- データパイプラインの問題
- ソフトウェアおよびハードウェアの構成管理に関する問題
- データパイプライン設計の潜在的欠陥
- データパイプライン実装の潜在的欠陥
- データセット全体に潜在する問題
- すべてのターゲットクラスのカバレッジが不十分で不均衡
- 内部で整合性のないデータ
- データ補強で歪んだデータ
- 最適でない特徴量選択
- 例/事例による潜在的な問題
- 欠損データ
- 間違ったデータ型
- 範囲外データ
- 外れ値と極値
- 誤ってラベル付けされたデータ
- 非代表的なトレーニングデータ
- 全ユースケースのサブセットに焦点を当てたデータ
- データ空間のすべての領域をカバーしていないデータセット
MLモデルのリスク
多くの点で、MLSのモデル部分は、他の小規模なシステムと同じように考えることができ、提供される機能に関連する一連の機能的リスクが存在し、それはシステムによって変化します。
しかし、MLモデルにはいくつかの特別な特徴があり、MLモデルに共通する以下のようなリスクを特定することができます:
- 機能的リスク
- モデルが学習した間違った機能
- 要求されるMLモデルのパフォーマンス指標を達成できない(精度や再現率の不足など)
- 本質的に確率的であり、非決定論的である。
- 偏った、あるいは不公平なMLモデル
- 非倫理的モデル
- 敵対的サンプル
- 過剰適合モデル
- 受け入れられないコンセプトドリフト
- 報酬ハッキングを示すモデル
- モデルは副作用を引き起こす
- モデル結果に対するユーザーの不満
- モデルAPIの欠陥
- 非機能リスク
- モデルの堅牢性の欠如
- 不十分なモデル性能効率
- モデル展開/使用
- 不適切なモデル構造(ターゲットプラットフォームへの展開など)
- モデルの文書化が不十分(機能、精度、インターフェースなど)
- モデル・アップデートがパフォーマンスを低下させる
開発リスク
既に述べたように、MLSは従来のシステムとは全く異なる方法で、アルゴリズムを用いて作成されています。ほとんどのデータサイエンティストは、MLSの作成をサポートするために専門的なML開発フレームワークを使用しています:
- ML開発フレームワークのリスク
- 最適でないフレームワークの選択
- フレームワークのインストールやビルドに不備があった
- 評価の不完全な実装
- アルゴリズムによって生成されたモデルに導入された欠陥
- 効率が悪い(例:フレームワークの応答が遅い、停止する)
- 貧弱なユーザーインターフェース
- APIの誤用(ライブラリへのAPI、TensorFlow APIなど)
- 使用ライブラリの欠陥(例:CNTKやPyTorchの欠陥)
- セキュリティの脆弱性
- ドキュメントの不備(ヘルプがないなど)
- MLアルゴリズムのリスク
- 最適でないアルゴリズム選択
- アルゴリズムに欠陥がある(アルゴリズムの実装に欠陥があるなど)
- 説明不足(例:選択したアルゴリズムの説明が難しい)
- トレーニング、評価、チューニングのリスク
- 不適切なアルゴリズム/モデルを選択
- 最適でないハイパーパラメーターの選択(ネットワーク構造や学習率など)
- トレーニング、検証、テストの各データセットへのデータの割り当てに欠陥がある(完全に独立していないなど)。
- 評価手法の選択ミス(n分割交差検証)
- 学習過程の確率的性質(例:非決定的な結果、テストの再現性の難しさなど)
- デプロイメントリスク
- デプロイの欠陥(ターゲットプラットフォーム用に間違ったバージョンを生成するなど)
- 運用環境との不適合
リスクの評価と対策
前述の通り、リスクスコアを算出するためのリスク評価は、影響度と確率の組み合わせに基づいて行われます。ここに挙げたMLS特有のリスクについては、一般的なプロジェクトにおける平均的な発生確率を見積もることができるかもしれませんが、影響は常にプロジェクト固有のものです。
特定されたリスクがテストによって処理できる場合、MLSのテストに特化した、リスク対策として選択可能ないくつかのテストタイプを特定することができます。以下に挙げるリスク処理のリストは、先に特定されたリスクに対する潜在的な処理として導き出されたものです。
インプットデータテストによるリスク対策
テスト入力データに関連するリスクについては、以下のML固有のテストタイプが処理として適用できます:
- データ・パイプライン・テスト
- データ・プロベナンス・テスト
- データ充足性テスト
- データの代表性テスト
- データの異常値テスト
- データセット制約テスト
- ラベルの正しさテスト
- 特徴量テスト
- 特徴量貢献テスト
- 特徴量効率テスト
- 特徴量と値のペアテスト
- 不公平なデータバイアステスト
加えて、非AIシステムにも用いられるデータガバナンステストも、データガバナンスが効果的でないリスクを扱うのに適切でしょう。
テストによるMLモデルのリスク処理
MLモデルの特異な特徴の一つに、その多く(特にディープニューラルネットワーク)の内部動作を理解することは、たとえアクセスできたとしても難しいということです。この点で、MLモデルは、内部動作の詳細にアクセスできない他のシステムに似ていると考えることができます。テストの観点からは、このようなシステムのテストに適した”一般的な”テスト技法があります。一般的な技法(すなわち、AI以外のシステムにも適用可能な技法)には、MLモデルのリスクを扱うのに適したものがあります:
- A/Bテスト
- APIテスト
- バックツーバックテスト
- 境界値分析
- 組み合わせテスト
- 探索的テスト
- ファズテスト
- メタモルフィックテスト
- リグレッションテスト
- シナリオテスト
- スモークテスト
- 性能効率テスト
このような一般的なテスト技法に加え、MLSのテストに特に有効なテストタイプやテスト技法もいくつか存在します:
- 敵対的テスト
- モデル性能テスト
- 代替モデルのテスト
- パフォーマンス測定テスト
- モデル検証テスト
- コンセプトドリフトテスト
- オーバーフィッティングテスト
- 報酬ハッキングテスト
- 副作用テスト
- ニューラルネットワークのホワイトボックステスト
- 倫理的システムテスト
- モデルのバイアステスト
- モデル・ドキュメントのレビュー
- モデル適合性審査
ML開発テストによるリスク対策
MLモデルの開発に関連するリスクを処理するのに適したいくつかの一般的なテスト技法が特定できます。開発フレームワークについて、広く使われているフレームワークでは、フレームワークの機能に関連するリスクは小さいと考えられるため、特定された技法のほとんどは非機能的なものです。対照的に、MLアルゴリズムの機能性はよく知られたリスクであり(ある研究では、これがMLSにおける欠陥の主な原因でした)、MLアルゴリズムをテストするためのいくつかの機能テスト技法が含まれています。MLSに適用可能で、非AIシステムにも使用される一般的なテスト技法は以下の通りです:
- APIテスト(開発フレームワーク)
- 構成テスト(開発フレームワーク)
- 設置性テスト(開発フレームワーク)
- セキュリティテスト(開発フレームワーク)
- パフォーマンステスト(モデルのトレーニング)
- 回復性テスト(トレーニング・データ)
- ロールバック・テスト(MLモデル)
- MLアルゴリズムのテスト
- コードレビュー(MLアルゴリズム)
- 静的解析(MLアルゴリズム)
- 動的ユニットテスト(MLアルゴリズム)
開発フレームワーク、MLアルゴリズム、MLモデルの配備に関連するリスクを扱うために、いくつかの専門的なテストタイプを特定することができます。これらのMLに特化したテストタイプには、以下のものがあります:
- フレームワーク適合性審査
- モデルの説明可能性テスト
- モデルの再現性テスト
- MLアルゴリズムのテスト
- アルゴリズム/モデルの適合性レビュー
- ライブラリ実装テスト
- モデル構造テスト
- アルゴリズムのバイアステスト
- デプロイメント最適化テスト
- モデルデプロイメントテスト
MLS – プロジェクトリスク
これまでのところ、MLSのRBTを通じて、プロダクトリスクと関連する処理が特定されています。これらは、成果物であるMLSがユーザーニーズを満たさないというリスクです。しかし、RBTを実施する際には、プロジェクトリスクも考慮する必要があり、MLSのテストの成功を脅かす明らかなプロジェクトリスクも存在します。
ここでは、テストに影響を与え、MLS特有のプロジェクトリスクのみを考慮します。もし、あなたがMLSのテストを担当するのであれば、テストの見積もりが不正確であったり、開発者がテスト対象のソフトウェアを合意通りに納品できなかったりといった、すべてのプロジェクトに適用されるテストに関する一般的なリスクも考慮しなければなりません。残念なことに、開発者がRBTを理解していないにもかかわらず、テスターに仕事の進め方について助言をする資格があると考える一般的なプロジェクトリスクは、MLSに携わるデータサイエンティストにも適用される可能性があります。
MLSのテストの成功を脅かす可能性のあるプロジェクトリスクの一例として、以下が挙げられます:
- MLSの経験豊富なテスターの確保が不十分である。
- MLSに関するテスター向けのトレーニングが不足している。
- MLS特有のテストタイプに精通したテスターは利用できない。
- 確率論的システムのテストアプローチが理解されていない。
- 非決定論的システムをテストするアプローチが理解されていない。
- 確率的システムの統計的検定のためのツールサポートが不足している。
- MLSのパフォーマンスメトリクスの定義は、受入基準として使用するには不十分である。
- コンセプトドリフトのための継続的なテストは考慮されない。
- ニューラルネットワークのホワイトボックスカバレッジ指標が未成熟。
MLSのテストは非AIシステムのテストとは異なるのか?
イエスでもあり、ノーでもあります。リスクベースのテストはすべてのシステムに適用すべきです。なぜなら、AIであろうと非AIであろうと、多くのシステムのリスクは常に異なるからです。
MLSには特定のリスクタイプがあるため、MLSのテストには、そのリスクを特別に扱い、MLSのテストにのみ有効なテストタイプを使用する場合が多いです。例えば、前のセクションでは、偏ったトレーニングデータに対する処理として、「不公平なデータバイアステスト」が挙げられました。このリスクとテストタイプは、通信システムのテストに特化したプロトコルテスト、コンピュータゲームのサウンドテストに特化したコンテンツ聴覚テスト、およびデータベースのテストに特化したスキーマ/マッピングテストと同様に、MLSのテストに特化しています。
AI専門テスターの必要性
これまで見てきたように、MLSのテストに特化したテストタイプや技法がいくつか存在します。つまり、MLSのテスト担当者は、これらのテストタイプや技法をどのように適用するかを知っておく必要があります。また、テスト対象のシステムの基礎となる技術を理解していることも、大きな利点となります。MLSのテストの場合、これはシステムがどのように構築されているかを理解することを意味し、非AIシステムのテスターには必要のないスキルです。
このように、MLSには特有のリスクがあるため、MLSシステムのテスターには専門的なスキルが必要とされます。同様の議論は、他のタイプのAIシステムのテスターが必要とするスキルにも当てはまります。AIベースのシステムの開発とテストを担当する者にとっての現在の課題は、このようなスキルを持つテスターが非常に少ないということです。これまでのところ、テスターに転身するデータサイエンティストはほとんどいません。データサイエンティストの現在の需要と高給を考えれば、彼らを責めることはできません。また、つい最近まで、従来の非AIシステムのテスターが、AIシステムのテストに自分のスキルセットを拡張したいと望む場合に利用できるトレーニングコースはほとんどありませんでした。幸いなことに、現在ではAIシステムをテストするためのISTQB認定資格があり、いくつかのトレーニングプロバイダーがそれをサポートしています。また、この分野のテスト標準も開発中であり、AIベースのシステムをテストするトピックの基礎を提供し、将来のトレーニングコースの開発をサポートするはずです。
結論
この記事ではまず、現代のプロフェッショナルなテスターにとってのベストプラクティスとして知られているリスクベースドテスト(RBT)の基本概念を紹介しました。RBTは、すべてのシステムのテストに使用されるべきであり、ISO/IEC/IEEE 29119シリーズのソフトウェアテスト標準によって義務付けられており、ISTQB認定資格の基本的な部分です。
AIはますます普及しつつありますが、AIシステムに対する一般の人々の不信感は高まっているようです。私たちはこの信頼の欠如に対処しなければならず、テストはその技術的解決策の重要な部分となっています(AIに関するユーザーとのコミュニケーションを大幅に改善する必要もある)。
機械学習システム(MLS)は、現在、AIシステムの中で最も広く使用されています。この記事では、リスクベースのテストアプローチを使用して、最も適切なテストタイプと技法を特定するために、MLSに関連するユニークなリスクをどのように使用できるかを示しています。
このようなMLS特有のテストタイプや技法は、ほとんどのテスターにとって初めてのものでしょう。より効果的かつ効率的なテストを通じてMLSに対する信頼を高めるためには、MLSに使用されるテストの成熟度を高める必要があります。これを達成するための第一歩は、MLSのテストが専門的なテストの中でも別個の専門分野であることを認識し、この専門分野をサポートする方法を特定することです。
この記事はReid博士の下記の記事を日本語に翻訳したものです。
オリジナル英語版はこちらに掲載しています。
■Risk-Based Testing for AI (English version/オリジナル英語版)