新卒でフロントエンド開発者をしています、イソダです。
先輩が作成した社内情報お問合せSlackBotをLangChainというツールを使用して、ベクターデータベースとChatGPTに接続して、より賢く、より人間らしい回答ができるようにシステム改修しました。今回はそのシステムについて簡単に紹介したいと思います。
(今回作成したシステムはまだ運用をしておらず、今後の運用を調整中です。)
LangChainとは
LangChainはChatGPTなどの言語モデルを活用したアプリケーションを開発するためのフレームワークです。利用方法としては、ChatBot、データベースやドキュメントなどの知識を元に質問に答えてくれるお問合せAI、ドキュメントの要約などいろいろあります。
今回はLangChainを使用して、社内制度へのお問合せSlackBotを作成していきます。
システム構成
作成したシステムの構成は次のようになっています。
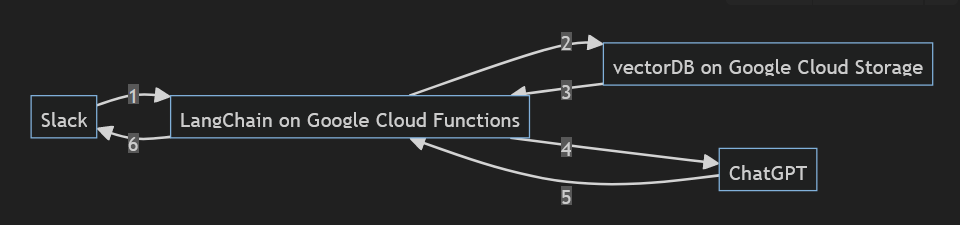
- まずSlackからの質問文をLangChainで受け取ります。
- これをLangChainからベクターデータベースにクエリとして送信します。
- すると質問文と関連があるドキュメントを抽出して返ってきます。
- 次にLangChainからChatGPTにドキュメントの内容を参考にして質問に答えるように指示を出します。
- そしてChatGPTから回答が返ってきます。
- 返ってきた回答をそのままSlackに返します。
LangChainはGoogle Cloud Functions、ベクターデータベースはGoogle Cloud Storage上に構築しています。
以降は、ベクターデータベースの作り方とLangChain、ベクターデータベース、ChatGPTとのやり取りについて説明していきます。
ベクターデータベースの構築
ベクターDBは、様々な形式のデータをベクトルとして保存し、クエリに対して類似度検索をして該当したデータを返してくれるデータベースです。
今回は社内向けのWebサイトに掲載されている情報を取り入れてベクターDBを作成しました。Webサイトをクローリングで取得してtxtファイルとして保存したものを利用しています。本記事ではクローリングについては説明しません。
以下がPythonで実装したベクターDB作成のコードです。
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders import DirectoryLoader
from langchain.text_splitter import CharacterTextSplitter
import dotenv
# OPENAI_API_KEYの読み込み
# (このコードがあるディレクトに.envファイルを作り、
# 中身に OPENAI_API_KEY=オープンAIのキー を書いておく)
dotenv.load_dotenv()
# データの読み込み
loader = DirectoryLoader("Webサイトのtxtデータがあるディレクトリ", glob="**/*.txt")
documents = loader.load()
# テキストデータを小さく分割
all_splits = CharacterTextSplitter().split_documents(documents)
# ベクターDBの作成
db = FAISS.from_documents(all_splits, OpenAIEmbeddings())
db.save_local("./faiss_index")
まずローカルに保存してあるWebサイトのtxtデータをDirectoryLoader&load()で読み込みます。引数のglobで拡張子がtxtであるファイルのみ読み込むよう指定しています。
次にベクターDBに格納するテキストデータをある程度の長さで分割していきます。この工程を行う理由としては、ベクターDBにクエリを出したときに帰ってくるドキュメントを短く、かつクエリと深く関連しているようにするためです。Webサイトなどのドキュメントは、1ページに複数個のトピックが書かれていることが多いです。これを短く分割することで、1つのドキュメントに含まれているトピックを絞り、クエリとは関連のないトピックが含まれることを防ぎます。
分割を行うインスタンスをCharacterTextSplitter()で呼び出し、分割を行う関数split_documents()に先ほど読み込んできたWebサイトのデータdocumentsを渡しています。
最後にベクターDBを作成します。今回はFAISSというベクターDBを使用しています。またテキストデータをベクトルに変換する埋め込みモデルはOpenAIのものを利用してます。FAISS.from_documents(ドキュメント, 埋め込みモデル)でベクターDBが生成されます。できたベクターDBは、db.save_local("./faiss_index")でローカル上のfaiss_indexディレクトリに保存します。faiss_indexディレクトリ内にindex.faissとindex.pklという2つのファイルが生成されます。
問合せシステムの構築
以下のコードがPythonで実装した問合せシステムです。モジュールはGoogle CloudとLangChainのものをインポートしています。以降の節で詳しく説明していきます。
import os
import functions_framework
from google.cloud import storage
from langchain_community.vectorstores import FAISS
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
from langchain_core.messages import HumanMessage
@functions_framework.http
def ai_question_vectordb_api(request):
try:
query_dict = dict()
question = request.get_data(as_text=True)
# GCSからベクターDBをダウンロード
storage_client = storage.Client()
bucket = storage_client.bucket("test_vecdb_for_langchain")
blob = bucket.blob("index.faiss")
blob.download_to_filename("/tmp/index.faiss")
blob = bucket.blob("index.pkl")
blob.download_to_filename("/tmp/index.pkl")
# ベクターDBにクエリ
vectorstore = FAISS.load_local("/tmp/", embeddings=OpenAIEmbeddings())
docs = vectorstore.similarity_search(question, k=3)
input_documents = str()
for d in docs:
input_documents += "input_documents: {}\n".format(d.page_content.replace('\n', ''))
# 問合せに対する回答を生成
llm = ChatOpenAI(model_name="gpt-3.5-turbo-16k", temperature=0, request_timeout=60)
query = input_documents
query += "question: {} ".format(question).replace('\n', ' ')
query += "questionに答えてください。"
answer = llm([HumanMessage(content=query)])
return answer.content
except Exception as e:
print(e)
return "ごめんなさい。。何か問題が起きたようです。。"
質問受付
@functions_framework.http
def ai_question_vectordb_api(request):
question = request.get_data(as_text=True)
一行目の@functions_framework.httpはGoogle Cloud Functionsで実装するときのおまじないみたいなものです。Slackから送られてきた質問をrequestで受け取ります。requestはただの文字列の想定なので、テキストとして読み込んでquestion変数に代入してます。
ベクターDBへのクエリ
# GCSからベクターDBをダウンロード
storage_client = storage.Client()
bucket = storage_client.bucket("test_vecdb_for_langchain")
blob = bucket.blob("index.faiss")
blob.download_to_filename("/tmp/index.faiss")
blob = bucket.blob("index.pkl")
blob.download_to_filename("/tmp/index.pkl")
# ベクターDBにクエリ
vectorstore = FAISS.load_local("/tmp/", embeddings=OpenAIEmbeddings())
docs = vectorstore.similarity_search(question, k=3)
input_documents = str()
for d in docs:
input_documents += "input_documents: {}\n".format(d.page_content.replace('\n', ''))
まずベクターDBであるFAISSをGoogle Cloud Storageからダウンロードして、ローカル上に保存します。今回はGCFs上の一時ファイル置き場として使える/tmpディレクトリ上に保存しています。ダウンロードするファイルは2つで、拡張子が.faissであるものと.pklであるものです。
次にローカル上に保存したベクターDBをメモリに読み込みます。
読み込みはFAISS.load_local(”FAISSがあるディレクトリ”, embeddings=OpenAIEmbeddings())で行います。ここで埋め込みモデルとして、ベクターDB作成時と同じモデルを指定します。読み込んだベクターDBに対してのクエリはvectorstore.similarity_search(質問文)で行います。このクエリの返答としては、質問文と類似度が高い文書が複数個返ってきます。今回はk=3で3つの文書を返すように指定しています。そして帰ってきた文書をinput_documentsに整形して格納します。
ChatGPTへのクエリ
# 問合せに対する回答を生成
llm = ChatOpenAI(model_name="gpt-3.5-turbo-16k", temperature=0, request_timeout=60)
query += input_documents
query += "question: {} ".format(question).replace('\n', ' ')
query += "questionに答えてください。"
answer = llm([HumanMessage(content=query)])
return answer.content
まずChatOpenAIをインスタンス化して変数llmに代入しています。このインスタンスは、OpenAIのgpt-3.5-turbo-16kモデルを使用してます。引数のtemperatureは0~1の値を取り、1に近いほどChatGPTが生成する回答文がランダムになります。今回はテストがしやすいように、値を0にして、同じ質問文に対しては同じ回答を返すように設定してます。あとは変数queryにChatGPTに送りたい文章を入れていきます。ここでは、ベクターDBが返した文章と、Slackから送られた質問文を整形して入れています。
そして、answer = llm([HumanMessage(content=query)])で実際にChatGPTと会話を行います。ChatGPTの回答はanswer.contentに入っているので、これをSlackにそのまま返しています。
動作例
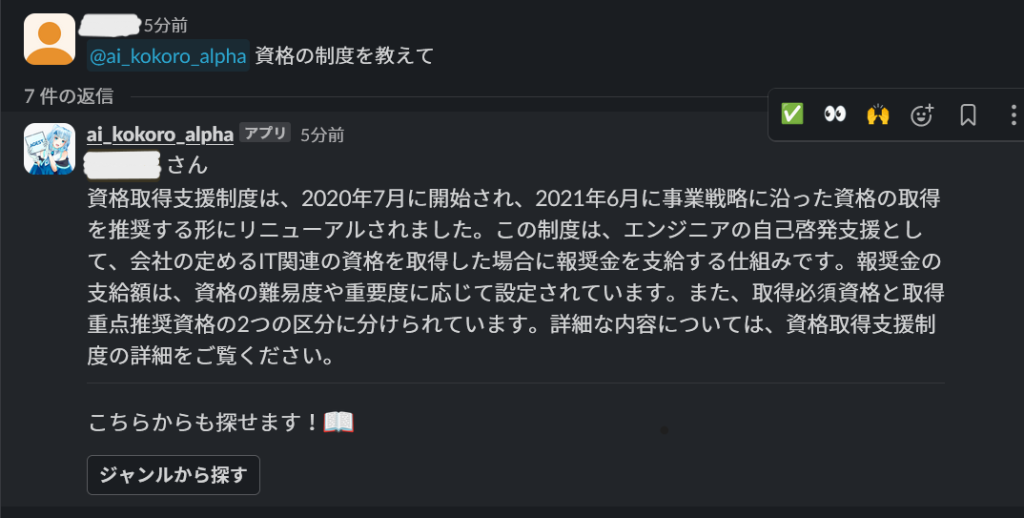
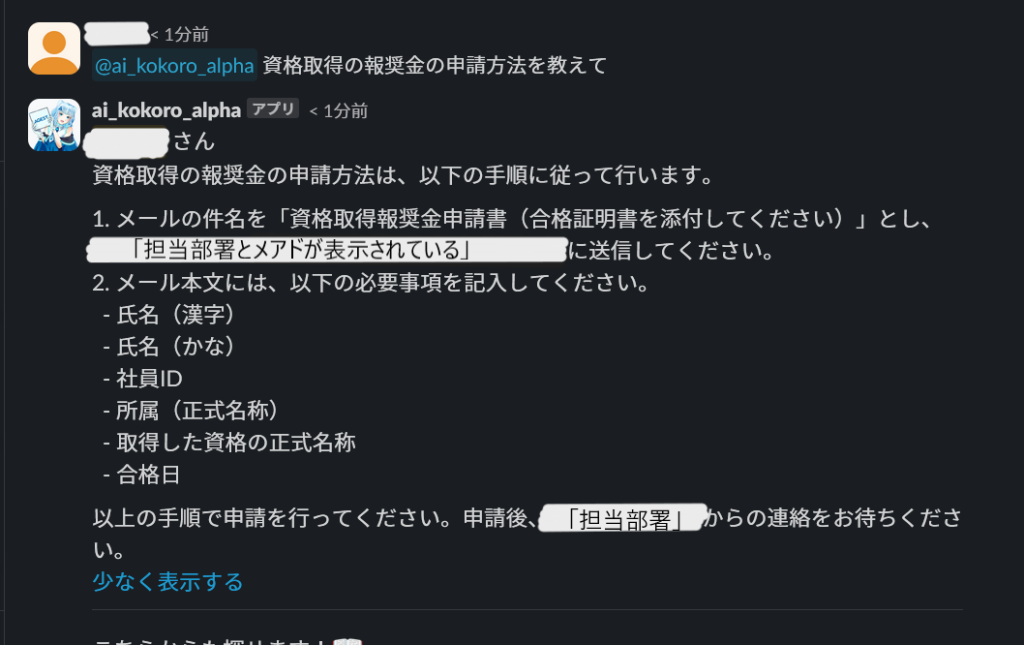
以下の画像が実際にSlack経由で実装した問合せシステムに質問した結果になります。試しに弊社の資格取得支援制度について質問したところ、社内情報に特化して、かつ自然な感じで回答してくれます。また「制度の申請方法を教えて」など質問する内容を詳細に絞ってあげると、それに対応して制度の細かい部分まで答えてくれます。
まとめ
LangChainを使うことで、ベクターDB+ChatGPTと連携してAIアプリが簡単に作成できました。今回は使用しなかったのですが、LangChainのChainという機能を使うことで、さらに簡潔に、かつデバッグがしやすくなるらしいです。以降はそのあたりも勉強しようかと思います。