こんにちは。 エンジニアの nobushi です。
RDBが必要な規模のデータを扱うWebアプリケーションを構築する場合、多少なりとも「検索」機能が求められるものだと思います。
しかし、この「検索」機能、要求事項の幅が非常に大きく、場合によっては実現がかなり難しいと思われることもよくあるんじゃ無いでしょうか。 「全文検索」はその代表とも思われるもので、機能自体はとてもメジャーなんですが、RDBだけでできることはそんなに多くありません。
そこで Elasticsearch のような全文検索エンジンを活用するケースも多いと思います。 ただその場合、データ更新をRDB、Elasticsearchの両方に対して行う必要があり、何かと煩雑になりがちです。
PGSync は PostgreSQL とElasticsearchの同期ツールで、PostgreSQLのデータ変更を即時にElasticsearchに反映してくれます。 そのため、アプリケーションではElasticsearchへのデータ更新を行う必要がなく、コードがスッキリします。
今回は簡単にPGSyncの導入をしてみたいと思います。
導入
docker-compose が使える環境で、任意のディレクトリに以下のファイルを配置して
/
db/
initdb.sh
postgresql.conf
pgsync/
Dockerfile
entrypoint.sh
schema.json
docker-compose.yml
配置したディレクトリで起動してください。
docker compose up -d
docker-compose.yml
services:
pgsync:
build:
context: ./pgsync
environment:
PG_HOST: db
PG_USER: postgres
PG_PASSWORD: hoge
ELASTICSEARCH_HOST: elasticsearch
depends_on:
db:
condition: service_healthy
elasticsearch:
condition: service_healthy
db:
image: postgres:16.0
environment:
- POSTGRES_PASSWORD=hoge
command: >-
-c "config_file=/etc/postgresql/postgresql.conf"
volumes:
- ./db/postgresql.conf:/etc/postgresql/postgresql.conf
- ./db/initdb.sh:/docker-entrypoint-initdb.d/initdb.sh
healthcheck:
test: ["CMD", "pg_isready", "-U", "postgres"]
pgadmin:
image: dpage/pgadmin4:7.7
environment:
- PGADMIN_DEFAULT_EMAIL=johndoe@example.com
- PGADMIN_DEFAULT_PASSWORD=hoge
ports:
- 50080:80
elasticsearch_prepare:
image: bash
privileged: true
user: root
command: ["sysctl", "-w", "vm.max_map_count=262144"]
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.10.2
depends_on:
elasticsearch_prepare:
condition: service_completed_successfully
environment:
discovery.type: single-node
xpack.security.enabled: "false"
ES_JAVA_OPTS: -Xms1g -Xmx1g
mem_limit: 2g
healthcheck:
test: ["CMD", "curl", "<http://localhost:9200>"]
interval: 1s
retries: 180
kibana:
image: docker.elastic.co/kibana/kibana:8.10.2
environment:
- ELASTICSEARCH_URL=http://elasticsearch:9200
depends_on:
elasticsearch:
condition: service_healthy
healthcheck:
test: ["CMD", "curl", "<http://localhost:5601>"]
ports:
- 55601:5601
PostgreSQL、Elasticsearchのインスタンスと、PGSyncのインスタンスを配置しています。
またPostgreSQL、ElasticsearchそれぞれのViewerとしてpgAdmin、Kibanaを配置しています。
db/initdb.sh
#!/bin/bash -xeu
set -o pipefail
psql -v ON_ERROR_STOP=1 <<- _EOT_
CREATE TABLE IF NOT EXISTS public.sample (id integer PRIMARY KEY, value text);
_EOT_
db/postgresql.conf
include = '/var/lib/postgresql/data/postgresql.conf'
wal_level = logical
max_replication_slots = 10
pgsync/Dockerfile
FROM python:3.11.5-alpine3.18
RUN apk update --no-cache &&\\
apk add --no-cache redis
RUN pip install pgsync==2.5.0
COPY entrypoint.sh .
COPY schema.json .
ENTRYPOINT ["sh"]
CMD ["./entrypoint.sh"]
pgsync/entrypoint.sh
#!/bin/sh -xeu
set -o pipefail
redis-server --daemonize yes
bootstrap --config schema.json
pgsync --config schema.json --daemon
pgsync/schema.json
[
{
"database": "postgres",
"nodes": {
"table": "sample"
}
}
]
PGSyncの設定
PGSyncはPythonのアプリケーションです。 上記 PGSyncサーバーの構築 ではPythonのコンテナイメージをベースにしています。 また、 Redis が必須なのでRedisも組み込んでます。
起動スクリプト ではRedisサーバーをバックグラウンド起動した後に以下のコマンドでPGSyncを起動しています。
bootstrap --config schema.json
pgsync --config schema.json --daemon
それぞれPGSyncの前準備、起動のコマンドです。 schema.json を引数として渡しています。
schema.jsonはPGSyncの対象テーブル等の設定を行います。 今回は最低限の設定として対象DBを postgres 、テーブルを sample としています。 この設定だと対象テーブルの全カラムをElasticsearchに同期することになります。 今回は割愛しますが、schema設定では対象のカラムを限定したり、スクリプトで値を加工したりと自由度は高いです。
動作検証
ではpgAdminとKibanaで確認してみます。
pgAdminへのアクセスは上記の docker-compose の通りであれば http://127.0.0.1:50080 で、
KibanaのDevToolへは http://127.0.0.1:55601/app/dev_tools#/console でアクセス可能なはずです。
pgAdminへのlogin
http://127.0.0.1:50080 にアクセスするとログイン画面が表示されるので
docker-compose の環境変数で設定した以下のメールアドレス、パスワードでログインします。
johndoe@example.com / hoge
pgAdminからDBへの接続
ログインしたらDBサーバーへの接続を追加します。
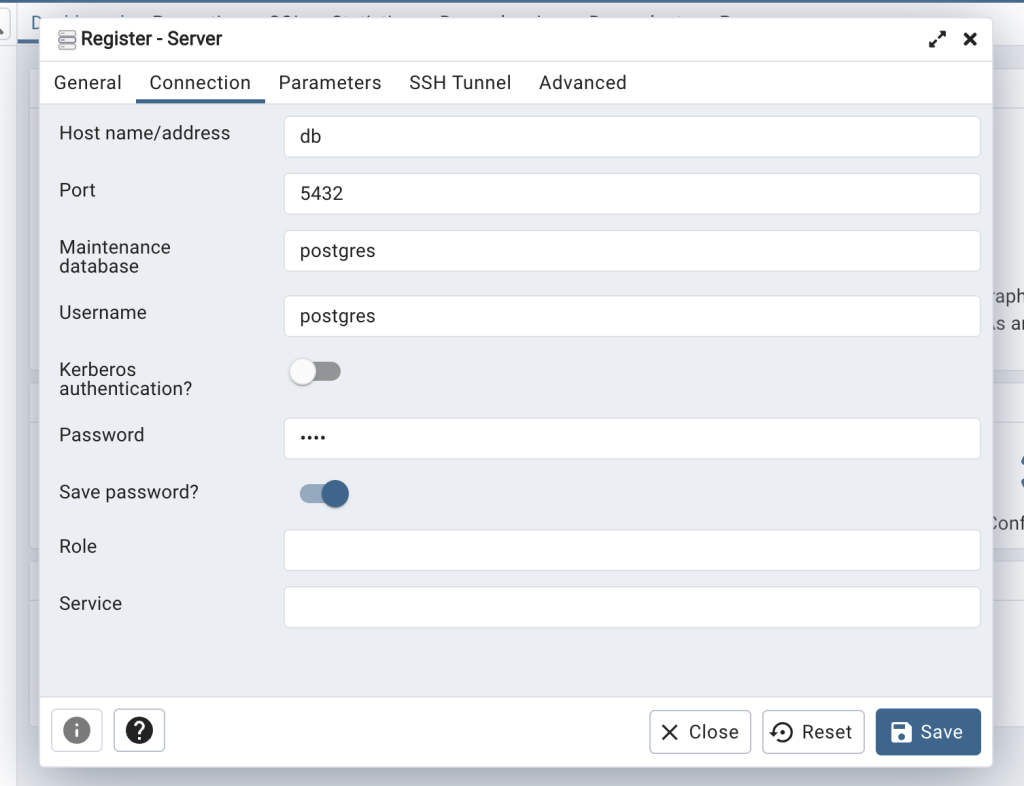
| General / Name | Connection / Host name | Connection / Username | Connection / Password |
|---|---|---|---|
| db | db | postgres | hoge |
この段階では sample テーブルは空です。
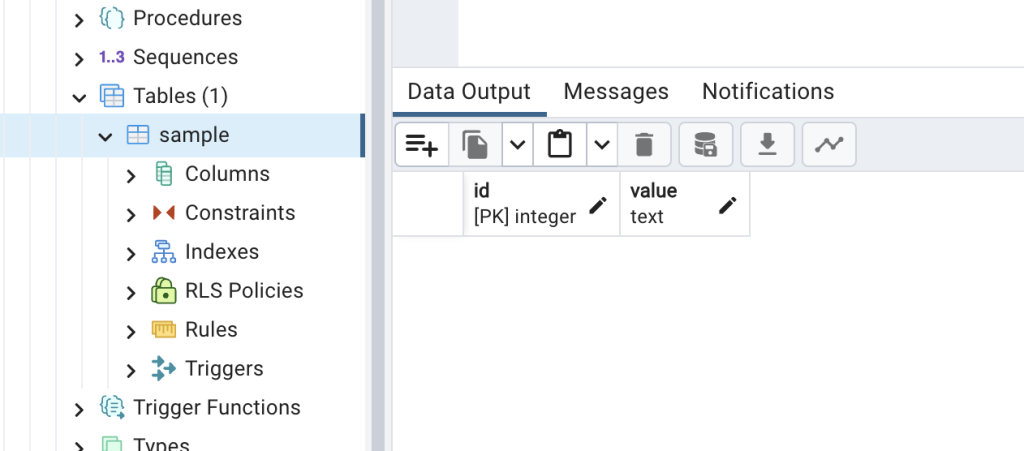
KibanaでElasticsearchの確認
http://127.0.0.1:55601/app/dev_tools#/console にアクセスするとKibanaのDevToolコンソールが表示されるので
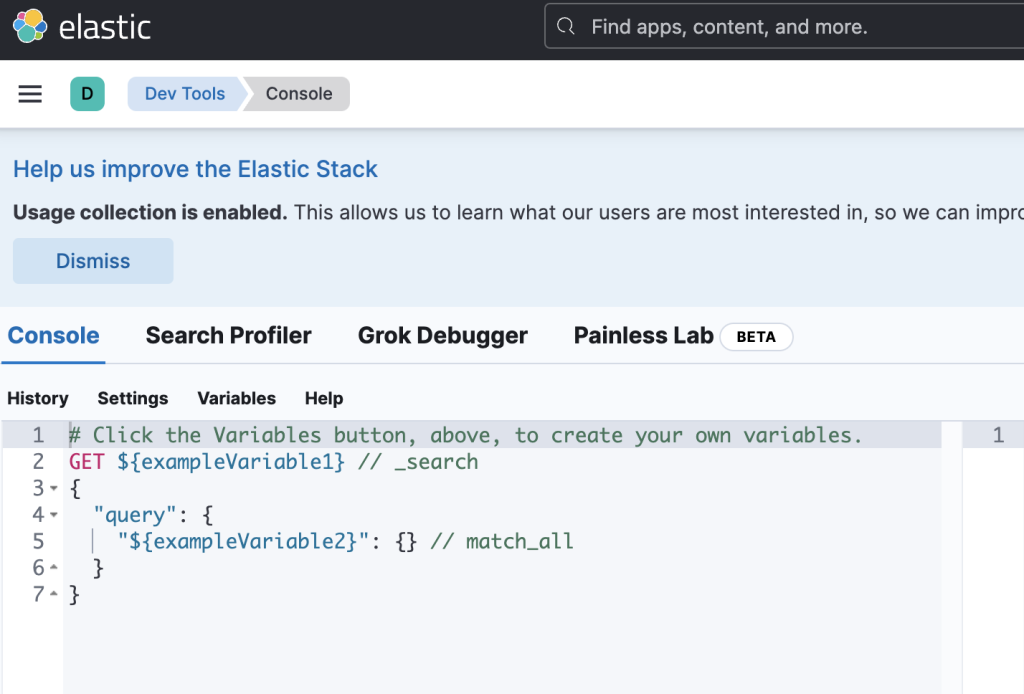
GET /postgres/_search
と入力して postgres インデックスの内容を表示します。
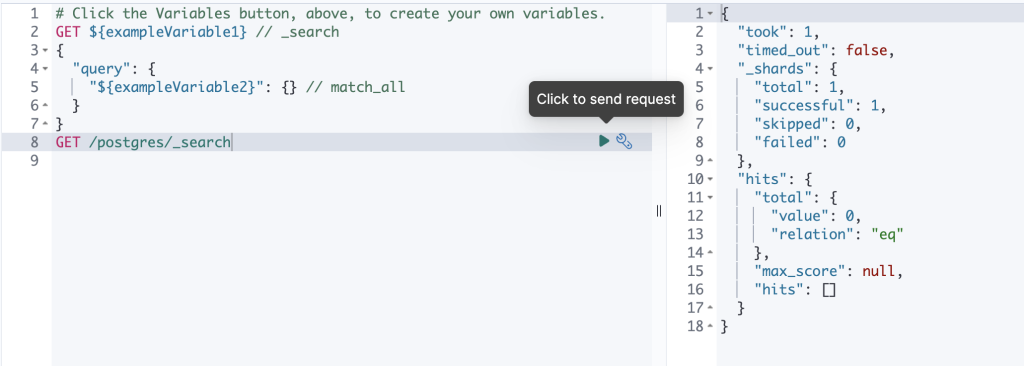
この時点では sample テーブルか空なのでElasticsearchのインデックスも空です。
PGSyncの動作確認
では、PGSyncが動作することを確認します。
pgAdminから sample テーブルにデータを追加します。
INSERT INTO public.sample VALUES (1, 'value1')
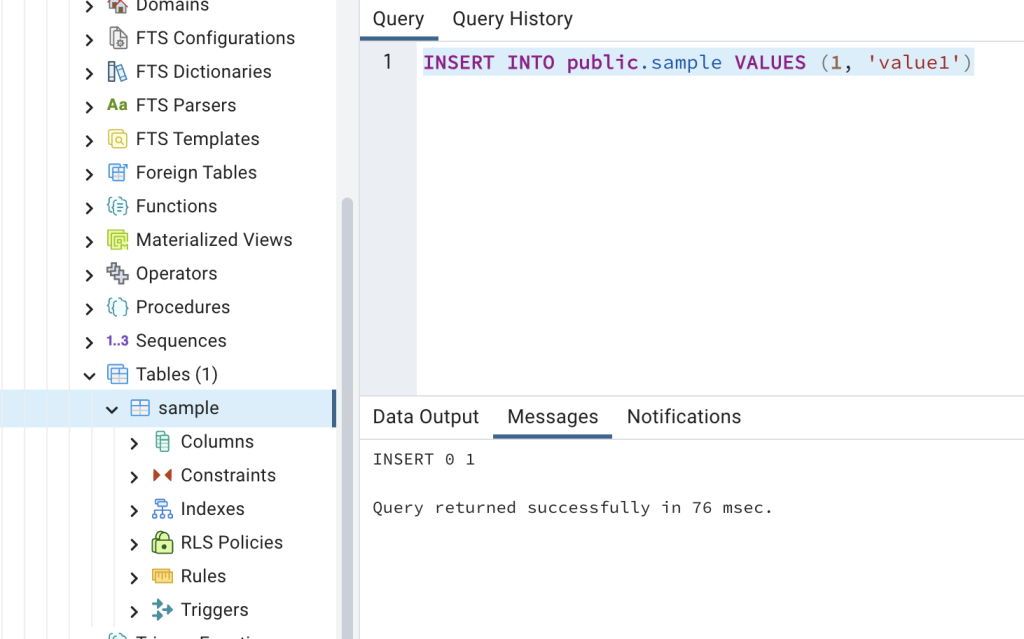
追加した後で、再度KibanaでElasticsearchを確認します。
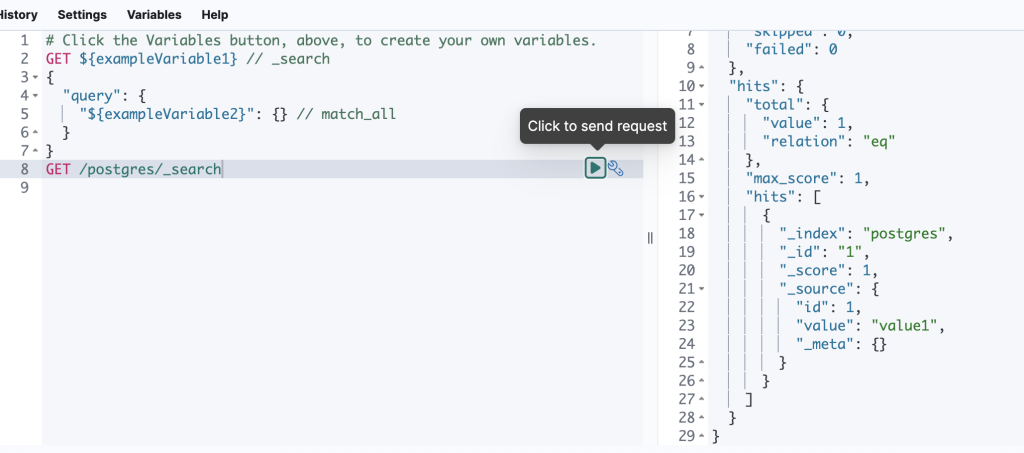
無事、Elasticsearchにデータが同期されていることがわかります。
所感
PGSyncによってPostgreSQLとElasticsearchの両方をアトミックに更新する必要がなくなるという点で、 利点は非常に大きいと思います。
使い方も難しくなく、また、Pythonのスクリプトが設定できるので自由度もかなり高いです。
Elasticsearchを使用する際には検討してはいかがでしょう。