AI が急速な進化を続ける中、各企業や私たちはその流れに遅れないようにする必要が出てきました。最先端の機械学習アルゴリズムから自然言語処理の進歩に至るまで、これらのトレンドは産業や私たちの日常生活を再構築する可能性を秘めています。
2023年以降も成熟する AI 市場に対して、私たちはAIをテストするという視点からAIに対してアプローチをしていきます。
AIテスティング(CT-AI)コースの紹介
今回紹介するのは、ISTQB(テスト技術者資格制度)の Foundation Level シラバス-AI テスティング (CT-AI)のトレーニングコースについてです。
一言で纏めてしまうとISTQBの資格取得用のトレーニングコースになるのですが、ソフトウェアテストの分野では世界的な権威でもあるスチュアート・リード博士がトレーナーを担当しており、博士の深い見識からもたらされるAIシステムにおけるテストの考え方を深く学ぶことができ、貴重な体験を得られます。
参考記事 【特集】AIのリスクベーステスト/スチュアート・リード博士
コース時間は12時間に及ぶコンテンツになっております。AI全般の技術や深い理解を醸成し、その実用化に向けて重要な洞察を提供してくれます。
内容は直接、ご覧いただきたいと思いますので、ここでは簡単な概要を紹介いたします。
セッション1:AIへの紹介
AIの基礎と導入に関する内容 AIの中核技術をお伝えし、GDPRのような法規制や特化型AI、従来の非AIとの違いなどを紹介。
キーワード:
適応性、アルゴリズムバイアス、自律性、バイアス、進化、説明可能性、説明可能な AI(XAI)、柔軟性、不適切なバイアス、解釈可能性、ML システム、機械学習、報酬ハッキング、堅牢性、サンプリングバイアス、自己学習型システム、副作用、透明性
セッション2:AIベースのシステムの品質特性
AIシステムの特に重要な品質特性について学び、ユーザーがAIシステムをどのように信頼するかを紹介。
キーワード:
適応性、アルゴリズムバイアス、自律性、バイアス、進化、説明可能性、説明可能な AI(XAI)、柔軟性、不適切なバイアス、解釈可能性、ML システム、機械学習、報酬ハッキング、堅牢性、サンプリングバイアス、自己学習型システム、副作用、透明性
セッション3:機械学習(ML) – 概要
機械学習の概要、モデルの評価やチューニングなどのワークフロー、機械学習モデルを利用した演習を通じて理解を深める。
キーワード:
アソシエーション分析、分類、クラスタリング、データ準備、ML アルゴリズム、ML フレームワーク、ML 機能性能基準、ML モデル、ML 訓練データ、ML ワークフロー、モデル評価、モデルチューニング、外れ値、オーバーフィッティング、回帰、強化学習、教師あり学習、アンダーフィッティング、教師なし学習
セッション4:ML – データ
MLにおけるデータの取得、準備、前処理の重要なステップ。
キーワード:
アノテーション、データ拡張、分類モデル、データラベリング、データ準備、ML 訓練データ、教師あり学習、テストデータセット、検証データセット
セッション5:ML機能パフォーマンスメトリクス
機械学習の評価指標に関する詳細な情報や算出方法の説明。
キーワード:
正解率、AUC、混同行列、F1 スコア、クラスター間メトリクス、クラスター内メトリクス、平均二乗誤差(MSE)、ML ベンチマークスイート、ML 機能パフォーマンスメトリクス、適合率、再現率、ROC(受信者動作特性)曲線、回帰モデル、R2 乗、シルエット係数
セッション6:ML – ニューラルネットワークとテスト
ディープニューラルネットワーク(DNN)などの基本的なキーワードを取り上げ、多層パーセプトロンやニューロンカバレッジのような高度なテクニックを紹介。
キーワード:
活性値、ディープニューラルネットワーク(DNN)、ML の訓練データ、多層パーセプトロン、ニューラルネットワーク、ニューロンカバレッジ、パーセプトロン、符号変化カバレッジ、符号-符号カバレッジ、教師あり学習、閾値カバレッジ、訓練データ、値変化カバレッジ
セッション7:AIベースのシステムのテスト概要
AIベースのシステムのテストに関する概要と課題について触れ、またコンセプトドリフトやデータパイプラインといったテストの際に考慮すべき事項について紹介。
キーワード:
AI コンポーネント、自動化バイアス、ビッグデータ、コンセプトドリフト、データパイプライン、ML 機能パフォーマンスメトリクス、訓練データ
セッション8:AIに特化した品質特性のテスト
AIの品質を評価するための特定のテスト技術と考え方を探求し、バイアスの検出、自律的なシステムの挙動、さらには解釈可能性や透明性を評価する方法など、AIの品質を確保するための多岐にわたるトピックを網羅。
キーワード:
アルゴリズムバイアス、自律型システム、自律性、エキスパートシステム、説明可能性、不適切なバイアス、解釈可能性、LIME 法、ML 学習データ、非決定論的システム、確率論的システム、サンプリングバイアス、自己学習型システム、透明性
セッション9:AIベースシステムのテストのための方法と技法
AIベースのシステムのテストに関するさまざまな方法と技術の紹介 AIで利用されるケースが多い、A/Bテストや敵対的テスト、メタモルフィックテストなども取り扱う。
キーワード:
A/B テスト、敵対的テスト、バックツーバックテスト、エラー推測、経験ベースのテスト、探索的テスト、メタモルフィック関係(MR)、メタモルフィックテスト(MT)、ペアワイズテスト、疑似オラクル、テストオラクル問題、ツアー,敵対的攻撃、敵対的サンプル、データポイズニング、ML システム、学習済みモデル
セッション10:AIベースのシステムのテスト環境
テスト環境に関する詳細なガイド ここでは自動運転車を例に取り上げ、仮想テスト環境のメリットやデメリットについての紹介。
キーワード:
仮想テスト環境、AI 専用プロセッサ、自律型システム、ビッグデータ、説明可能性、マルチエージェントシステム、自己学習型システム
セッション11:テストにAIを使う
テストプロセスにAIをどのように組み込むか、および実際の演習を通じての学び。
キーワード:
ビジュアルテスト、ベイジアン手法、分類、クラスタリングアルゴリズム、欠陥予測、グラフィカルユーザーインターフェース(GUI)
1. AI業界のこれから
AIは現代のエンジニアリング分野において重要な役割を果たしており、その市場規模は急速に拡大しています。
特に生成AIの経済的ポテンシャルに関するマッキンゼーのレポートを要約すると生成AIの導入は、世界経済に年間約2.6兆ドルから4.4兆ドルの価値をもたらす可能性があり、現在使用されているソフトウェアに組み込まれることで、その価値はさらに2倍になる可能性があります。
生成AIはすべての産業構造に著しい影響を与えると予測されており、顧客サービス、マーケティング、販売、ソフトウェアエンジニアリング、研究開発などの分野で特に大きなビジネス価値を提供することが予想されています。
いくつかのユースケース分析を通じて、AIが様々なビジネス課題に対処し、測定可能な成果を出すことが示されています。
生成AIは労働市場にも影響を及ぼし、現在従業員が行う作業の60~70%を自動化する可能性があることから、仕事の構造を変化させることが予測されています。
この技術の自動化の可能性は、特に自然言語理解の能力が向上することにより加速しています。 この移行は労働者に新しいスキルの習得や職業の変更を要求し、それをサポートするための投資が必要と示しています。
このようにテクノロジーの絶え間ない進歩により、将来的にはさらに大きな進歩が期待でき、未来を形作る上でテクノロジーがますます重要な役割を果たすことは間違いありません。
参考: 2023年 国内AIシステム市場予測を発表
参考: The economic potential of generative AI: The next productivity frontier
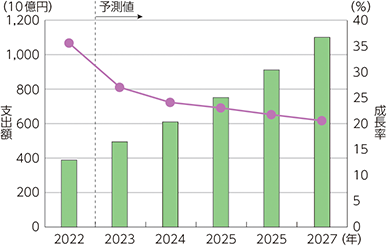
次の生産性フロンティア(マッキンゼーの見解)
では将来に向けてどのように備えればよいでしょうか? 私たちは更に認識を広め、自分自身を教育していくことを継続していく必要があると思います。
AIは反復的なタスクを自動化し、人間の時間を節約するという驚異的な能力を備えてくれています。 これは私たちがより複雑で創造的な取り組みに集中するのに役立つツールだということです。
AI はさまざまな業界の多くのデータ分析に役立ち、あらゆるタスクを最適化し、効率とコスト効率を高めてくれると思います。
AIの未来は明るく、適切なアプローチをとれば、私たちは AI テクノロジーの進歩の恩恵を受けながら、その課題にも取り組むことができます。
AIテスティング(CT-AI)コースは、この急成長している分野でのキャリアを志向するエンジニアにとって、必要な知識と技術を習得する絶好の機会を提供します。
このコースでは、AIの基本原理から最先端の応用に至るまで幅広いトピックが網羅されており、特にAIベースのシステムの品質特性やテスト方法に重点を置いています。
参加者はAI技術の進歩に対応するための実践的なスキルと理解を深めることができます。
2. AIシステムのテストや評価の難しさについて
コースにおいてもAIシステムのテストや評価の難しさを取り上げています。
これらの要因は、AIの複雑性、不透明さ、そして動的な性質から生じるものです。
以下に、これらの要素をいくつか紹介し、機械学習システムの失敗例とテストの重要性を示します。
【AIの複雑性とブラックボックス問題】
| 問題 | 説明 |
|---|---|
| 複雑性とブラックボックス問題 | AIシステムは通常「ブラックボックス」と見なされ、システムがどのようにして特定の出力や決定に至ったかを外部から理解することは困難です。 ニューラルネットワークなどのモデルは数百万のパラメータを持ち、これらが最終出力にどう影響するかの理解は難しいです。 |
| データ依存性 | AIモデルは訓練データに大きく依存しており、データセットに偏りがある場合、不正確な結果を出す可能性があります。 訓練データと異なる新しいデータに対する反応を予測するのは難しいです。 |
| 動的な学習プロセス | 多くのAIシステムは新しいデータから学習を続け、システムの振る舞いが時間と共に変化する可能性があります。 この動的な学習プロセスはテストや評価を継続的に行う必要があり、大量の資源を消費する可能性があります。 |
| 解釈可能性と透明性 | AIシステムの決定を人間が理解し信頼するためには、その決定過程を説明できる必要があります。 解釈可能性と透明性の欠如はテストと評価を複雑にします。 |
| エラーの特定と修正 | AIシステムが誤った決定をした場合、その原因の特定と修正は難しく、AIモデルの規模が大きく複雑であればあるほど困難です。 |
| 不確実性とリスクの管理 | AIシステムには確率的要素が含まれ、予測や決定に不確実性が伴います。 この不確実性を適切に管理し、リスクを最小限に抑えることはAIテストと評価の重要な課題です。 |
【機械学習(ML)システムの失敗例】
| 問題 | 説明 |
|---|---|
| 偏ったデータセット | ある人種や性別に偏ったデータセットで訓練された顔認識システムは、特定のグループに対して誤った識別を行うことがあります。 これは偏見を持った意思決定につながり、社会的な不公平を生じる可能性があります。 |
| オーバーフィッティング | 訓練データに過度に適合したモデルは、新しいデータに対してうまく機能しない可能性があります。 これは、モデルがトレーニングデータのノイズやランダムな変動を学習してしまうためです。 |
| リアルタイムデータへの適応の欠如 | 市場予測のモデルが過去のデータに基づいて構築され、市場の新たな動きに迅速に適応できない場合、不正確な予測を行うことがあります。 |
| 不十分なテストと検証 | 医療診断をサポートするために設計されたMLシステムが、十分な検証を経ずに臨床環境で使用されると、誤診や治療の遅れを引き起こす可能性があります。 |
【テストの重要性】
| テストの重要性 | 説明 |
|---|---|
| バイアスの低減 | テストは、モデルの決定に偏りがないことを確認するために不可欠です。 これにより、公平で倫理的なAIシステムの構築が可能になります。 |
| 汎化能力の評価 | モデルが新しい、未知のデータにうまく対応できるかどうかをテストすることで、その汎化能力を評価します。 |
| パフォーマンスの検証 | 正確性、再現率、適合率などのメトリクスを用いて、モデルのパフォーマンスを検証します。 これにより、特定の用途に対してモデルが適切かどうかを判断できます。 |
| 安全性と信頼性の保証 | 特に医療、金融、自動運転車などの分野では、モデルの安全性と信頼性の確保が必要です。 |
| 継続的な改善 | テストは、モデルの弱点を特定し、継続的な改善を行うための基盤を提供します。 機械学習システムのテストと評価は、これらのシステムが現実世界で効果的かつ倫理的に機能するために不可欠です。 |
これらの要因により、AIのテストや評価は伝統的なソフトウェアテストよりもはるかに複雑で挑戦的な作業である事が判ります。
※参考までに機械学習の失敗事例を載せておきます。
- キヤノンITS -なぜ上手くいかなかったのか 機械学習
- WebBigData – 機械学習のトレーニングに失敗したしくじり事例
- tjo.hatenablog.com – 機械学習プロジェクトが失敗する9つの理由
- スタビジ -AIプロジェクトの失敗する原因3
- ソフトバンク – なぜAI導入は失敗する? 失敗事例から学ぶ傾向と対策
- Aidemy Business – AI導入の失敗あるある、「PoC死」の罠とは?
3. トレーニングコースで学べる事
各セッションの内容は多岐にわたり、AIベースのシステムの品質特性や機械学習の基本、訓練データの取り扱い、MLモデルの評価指標などに焦点を当てています。
さらに、AIベースのシステムのテスト方法、AI固有の品質特性とテスト問題、テスト環境の構築、そしてAIをテストプロセスに組み込む方法など、実践的なテスト技術に関する詳細な情報も提供しています。
このようにコンテンツ量が多く専門的な用語も豊富なため、全てをお伝えするのは難しいですが、いくつかの主要なトピックを紹介したいと思います。
機械学習(ML)
コース概要からも判る通り、本講義では機械学習(ML)という用語が頻出します。
本コースでは、AIにおける最も人気のあるアプローチとして機械学習に重点が置かれています。
機械学習には、回帰/分類/クラスタリングがあり、講義でも取り扱っている内容です。
●回帰 (Regression)
【用途】: 連続する値や量の予測
・株価予測
・不動産の価格予測
・気温の予測など【主なアルゴリズム】
・線形回帰 (Linear Regression):
連続値の予測に使用される
・多項式回帰 (Polynomial Regression):
非線形関係をモデル化する際に使用
●分類 (Classification)
【用途】 データをクラス/カテゴリに分類
・顔識別
・スパム判定
・病診断など
【主なアルゴリズム】
・ロジスティック回帰: 2クラス分類用
・決定木: 階層分割で分類
・ランダムフォレスト:
決定木のアンサンブル学習
・SVM: 分類境界を最適化
●クラスタリング (Clustering)
【用途】ラベルのないデータ(教師なし学習)を類似性に基づいてグループ化
・顧客のセグメンテーション
・遺伝子クラスタリング
・SNS上のトレンドの識別など
【主なアルゴリズム】
・K-平均法: データをK個のクラスタに分類
・階層的クラスタリング:
データをツリー構造のクラスタに分類
機械学習と一口に言っても、様々な手法があり、実際の使われ方にも多様な種類があります。ニューラルネットワークの仕組みを利用したディープラーニングは今のAIにおいて多大な貢献をもたらした技術です。
いくつか代表的な例を紹介しておきます。
| 使用技術: | 畳み込みニューラルネットワーク(CNN) |
|---|---|
| 顔認証 | ロック解除、防犯、など… |
| 画像の分類 | 写真の分類、 医療画像解析、など… |
| 使用技術: | 敵対的生成ネットワー ク(GAN) |
|---|---|
| 画像・動画の生成 | 線画の着色、テキストから画像生成、ロゴデザイン、動画コンテンツの生成 など… |
| ゲームの再現 | 名作ゲーム「パックマン」の完全再現、など… |
| 使用技術: | 再帰型ニューラルネットワーク(RNN) |
|---|---|
| 文章の理解 | 商品レビューの分析、 音声アシスタント、 問題文の読解、スパムフィルタ、 など… |
| 文章の生成 | 文章の要約、 チャットボット 、機械翻訳、 など… |
一例ではありますが、ディープラーニングの種類は実に豊富で、多くの事業に活用できるテクノロジーであることが証明されています。 本コースでもニューラルネットワークについて取り上げており、シンプルなパーセプトロンを実装する演習などが用意されています。
機械学習モデルの評価指標
これら代表的なタスクのほかに、機械学習では、データの前処理やモデルの構築、モデルの評価と、さまざまな技術や手法が紹介されています。 特にテストや評価に密接に関わるであろう、モデルの評価指標について、いくつかの重要な概念とそれらの基本的な説明を紹介しておきます。

以下の表と図で混合行列のマトリクスを用いて紹介します。
混同行列(Confusion Matrix)は、主に機械学習において、分類モデルの性能を評価するために使用されるツールです。この行列は、分類問題の実際の結果と予測された結果を比較するために使われ、以下の四つの要素で構成されます
| 左上: | True Positive (真陽性:TP): 正しい陽性の予測。 実際に陽性であり、モデルが陽性と正しく予測したケースの数。 |
| 左下: | False Positive (偽陽性:FP): 誤った陽性の予測。 実際には陰性であり、モデルが誤って陽性と予測したケースの数。 |
| 右上: | False Negative (偽陰性:FN): 誤った陰性の予測。 実際には陽性であり、モデルが誤って陰性と予測したケースの数。 |
| 右下: | True Negative (真陰性:TN): 正しい陰性の予測。 実際に陰性であり、モデルが陰性と正しく予測したケースの数。 |
【この図は正解ラベル(横軸)に対してモデルが正解/不正解の予測(縦軸)を示す指標です】
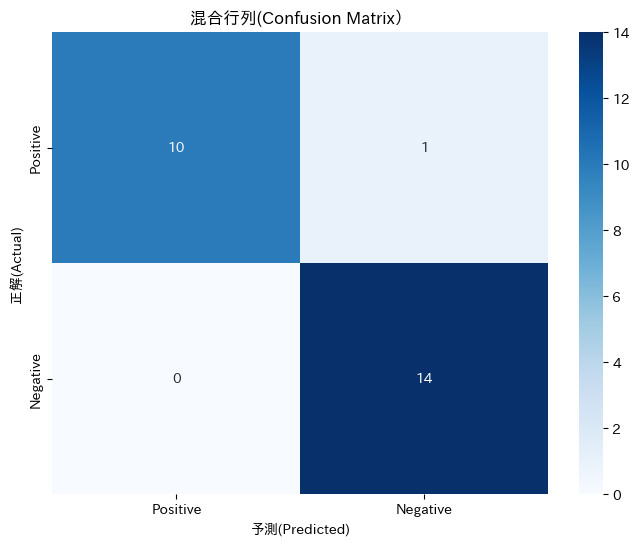
これら4つの要素を使って、正解率、適合率、再現率、F1スコアなどを算出できます。 これらはモデルの特性やデータが不均衡な場合は誤解を招く可能性がありますので、1つの指標だけでなく複数の指標を用いて多面的に評価をしていく必要があります。 ここでは分類モデルの評価指標の一例を紹介しました。
さて、コースにおけるいくつかのコンテンツを紹介させて頂きましたが、ここですべてを説明することは割愛させて頂きます。今までの内容からAIテスティングに興味が湧いた方は、是非、お手に取って頂ければと思います。
今回紹介した内容以外にも
💡 AIに特化した品質特性 アルゴリズムやサンプルのバイアス、独自に進化する自己学習システムや自らを制御する自律型システムなどどのように予測精度や意思決定の品質を評価していくかを課題として取り扱っています。
💡 AIのテスト環境 現実的に環境構築が難しいケースを構築できるメリットを上げており、危険なシナリオ、異常なシナリオ、極端なシナリオ、時間のかかるシナリオなどに対して、観測や制御が容易であるメリットを説明しています。
💡 テストにAIを使うケース 欠陥の分析や予測、テストケースの生成やユーザーインターフェースのテストなどが取り上げられています。一例ではありますが、例えば今回紹介したような、SVMやk近傍法などを用いる事で、適切な欠陥カテゴリを特定し、類似した欠陥や重複した欠陥を分類したり、ファジー理論やベイズ理論等の応用で、事前確率と新たなデータを組み合わせて、事象の発生確率を更新し予測を行うなどに用いる事例が紹介されています。
多様にあるAIベースのシステムに対して、ソフトウェアの品質をどのように達成するか、そのヒントを提供してくれると思います。
4.最後に
ChatGPTの動向
今回AIの題材を扱わせて頂きましたが、2022年にChatGPTとMidjourneyの登場により、生成AIの波が到来しました。特に、ChatGPTを中核とする大規模言語モデル(LLM)に関するニュースは日々飛び交い、その急速な進化には驚嘆させられます。 多くの企業がLLMをビジネスに導入し、新規サービスの開発、既存事業の拡張、効率化のために活用しています。そして2023年11月7日、OpenAIはChatGPTを大幅にアップデートし、その波はさらに加速しています。
このコースでは大規模言語モデル(LLM)の直接的な扱いはありませんが、LLMの使用を通して、その評価の複雑さを理解することができます。 現代のテクノロジーの中心にあるChatGPTのようなLLMが作り出すテキストの精度を測ることは、非常に困難な課題です。 この根幹にあるのは、特定の期待される出力に対して明確な基準を設定することの難しさと、同じ入力に対しても一貫性のある結果を得られるとは限らない、という特性にあります。これらの要素はLLMのテストと評価を複雑にしており、我々がこの分野で直面する主要な問題の一つとなっています。
LLMの評価指標は新しい研究分野ですので標準的な指標セットや、評価ツールも発展途上という状態です。 その中でいくつか参考となる内容を紹介しておきますので、興味がある方はご覧ください。
- 例えば、ChatGPTのAPIであるLangChainの評価機能の中で特に埋め込み距離(embedding distance)を扱う部分に焦点を当てています。
LangChainを使って自然言語処理タスクを実行し、その結果を評価するための機能やメソッドの説明がされています。
langchain.evaluation.embedding_distance.base.EmbeddingDistanceEvalChain — 🦜🔗 LangChain 0.0.336 - またGitHubページに、OpenAIによる「HumanEval」という問題解決データセットの評価ハーネスに関するものがあります。
このデータセットは、コード上で訓練された大規模言語モデルの評価を目的としており、「Evaluating Large Language Models Trained on Code」という論文で詳細が述べられています。
https://github.com/openai/human-eval
AI の時代はまだ始まったばかりです。しかし、この技術の利点を完全に実現するには時間がかかり、ビジネスや社会は依然として対処すべき大きな課題を抱えています。
これには、生成 AI に内在するリスクの管理、従業員に必要な新しいスキルや能力の決定 新しいスキルの再トレーニングや開発などの中核となるビジネスプロセスの再考などが含まれます。今後のAI時代に向けて、AIをテストするというアプローチから、AIに関する基本的な知識や理解を深め、今後の発展に役立ててくれると嬉しく思います。
Udemyクーポン配布
2023.12.25更新
Udemyの割引クーポンの発行(カスタム価格 1,900円)
クーポンコード: 6FCB681BDB2184AFC23E
有効期限: 2023/12/26 17:00~2024/1/26 17:00 (JST)
ぜひご活用ください。
<おすすめ記事・メディア>
・Udemyのセール情報はこちらから 【Udemyセール最速更新】次のセールはいつ?最大95%割引【2024年1月】