こんにちは。 エンジニアの nobushi です。
今回は Python のマイグレーションツール Alembic を実際に運用してみたいと思います。
以前の ブログ で Alembic を紹介しましたが実際にどう運用するかについてまでは触れませんでした。 今回は GCP の CloudRun を主体としたシステムでの運用方法について紹介したいと思います。
CloudRun
CloudRun は GCP のサーバーレスなコンテナ実行環境で、とても簡単にコンテナを実行することができます。 ロードバランサも内蔵されていてリクエスト数に応じて自動的にスケーリングしてくれるため、 特に何もしなくても堅牢なコンテナアプリケーションを運用できます。
しかし、この CloudRun ですが何でもできるというわけではなく HTTP 、 gRPC 等のリクエストを契機としてその処理中のみ動作する、というのが基本になっています。
ここで問題になるのが Alembic のマイグレーションです。 Alembic のマイグレーションはコマンドで動作する仕様のためコマンドの実行が必要です。 HTTP リクエストを契機としてコマンドを実行するという手もありますがセキュリティホールになりかねません。
CloudRun のままではマイグレーションを実行するのは難しそうです。
ComputeEngine
ComputeEngine はプレーンな仮想マシンです。 実行に際して特に制限等がない代わりにマシンスペック、スケーリングの管理等は全て自分で行う必要があります。
もちろんコマンドを実行することも問題なくできるので Alembic のマイグレーションも実行できます。
CloudRun がオールインワンで運用しやすいのに対して ComputeEngine は自由度が高い代わりに手間がかかる、 と言ったところでしょうか。
運用案
前述の通り ComputeEngine は自由度が高く任意のコマンドも実行できるので Alembic のマイグレーションを実行するのにも特に不都合はありません。 ただし管理の手間がかかりますので、できればサーバーレスである CloudRun を使用したいというケースも多いと思います。
そこで CloudRun を主体として運用しながら Alembic のマイグレーションには ComputeEngine を使う、という方法です。
CloudRun はコンテナの実行環境ですが ComputeEngine もコンテナをそのまま実行可能です。 そのため同じアプリケーションを動かすのは難しいことではありません。
イメージとしては以下の通りです。
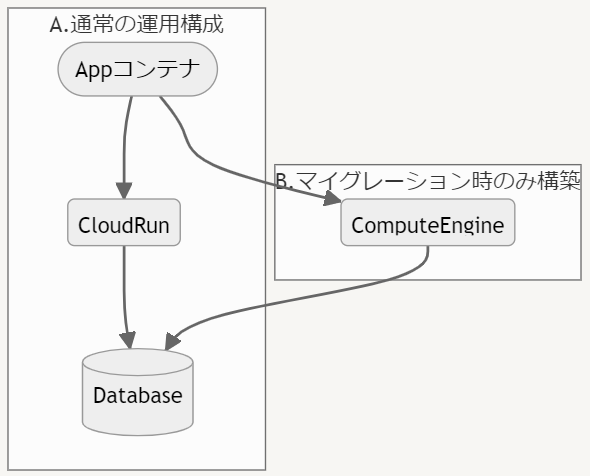
A は運用時の構成で、 アプリケーションのコンテナを CloudRun で実行し CloudRun は Database に接続しています。
しかし、このままでは前述の通り Alembic のマイグレーションを実行することができません。 そこで、マイグレーションが必要な変更のデプロイ時に B の構成を一時的に立ち上げます。 B は A と同じコンテナを実行し、同じデータベースに接続します。
この B でマイグレーションを実行し、完了したら削除します。
Terraform
Terraform の場合、前述の [A.通常の運用構成] と [B.マイグレーション時のみ構築] を別々の実行単位(ディレクトリ)で構築します。
以下はマイグレーション側のterraformの例です。
terraform {
backend "local" {}
}
provider "google" {
project = "<project-name>"
region = "us-west1"
zone = "us-west1-c"
}
variable "container_image" {}
data "google_sql_database_instance" "db" {
name = "db"
}
data "google_service_account" "app" {
account_id = "app-sample"
}
module "app_container" {
source = "terraform-google-modules/container-vm/google"
version = ">= 3.1.0, < 3.2.0"
container = {
image = "${var.container_image}"
command = ["sh"]
args = ["-c", "alembic upgrade head"]
env = [
{
name = "DB_HOST"
value = "${data.google_sql_database_instance.db.private_ip_address}"
},
]
}
}
resource "google_compute_instance" "migration" {
name = "migration"
machine_type = "e2-micro"
boot_disk {
initialize_params {
image = module.app_container.source_image
}
}
network_interface {
network = "default"
access_config {}
}
metadata = {
gce-container-declaration = "${module.app_container.metadata_value}"
}
service_account {
email = data.google_service_account.app.email
scopes = [
"<https://www.googleapis.com/auth/cloud-platform>",
]
}
}
ポイントは以下の通りです。
terraform {
backend "local" {}
}
マイグレーション実行後には破棄すれば良いのでバックエンドはローカルに設定しています。
data "google_sql_database_instance" "db" {
name = "db"
}
data "google_service_account" "app" {
account_id = "app-sample"
}
データベースインスタンスとアプリケーション用のサービスアカウントは [A.通常の運用構成] の側で管理されている前提です。 そのため、こちらではすでにあるインスタンスを参照することになるため data で記述します。
module "app_container" {
source = "terraform-google-modules/container-vm/google"
version = ">= 3.1.0, < 3.2.0"
container = {
image = "${var.container_image}"
command = ["sh"]
args = ["-c", "alembic upgrade head"]
env = [
{
name = "DB_HOST"
value = "${data.google_sql_database_instance.db.private_ip_address}"
},
]
}
}
コンテナは [A.通常の運用構成] と同じものを私用しますが起動コマンドが異なります。 [A.通常の運用構成] ではWebサーバーの立ち上げコマンドを指定しているはずですが、 こちらでは Alembic の実行コマンドを指定しています。 これによりこちらのサーバーではマイグレーションを行うだけでコンテナは終了します。
この .tf ファイルを実行者のPC等から実行し、 ログ等でマイグレーションの正常終了を確認したらこのコンテナ環境自体が不要なので破棄 (destroy) します。
所感
マイグレーションを実行する場合には CloudRun のように自由度が低い場合に困りますが コンテナが主体であれば一時的に別のコンポーネントで実行することは簡単なので そういうアプローチで良いと思います。
また、マイグレーションを行うだけであれば終わったら破棄する前提にできるので セキュリティについてはあまり考慮しなくても大丈夫、という点もポイントです。