




本連載では、ブロックチェーンの基本的な仕組みを解説しながら、オンチェーンデータを分析するための基本的な手法について、全8回で紹介します。
最終回となる今回は、過去の連載記事で紹介しきれなかったDune(分析ツール)のTips的な有用機能や、分析のための高度なSQL構文についてご紹介します。
Dune Tips
DuneのようなSQLベースの分析ツールは、SQLで記述されたクエリを再利用するためのさまざまな有用機能が実装されていることが多くあります。その中でも、多くの分析ツールで頻繁に使用されるパラメタ化機能やビュー作成機能についてご紹介します。
Parameters
SQLクエリ中の絞り込み条件に含まれる、時刻や特定の文字列などの値を、パラメタ化して実行時に指定できるようにしたり、パラメタだけを変えて同じクエリを何度も実行したりしたいことがよくあります。Duneの場合、パラメタ化したい箇所に名前をつけて {{ }} で囲うことで、簡単にパラメタの外部化を実現できます。コード1に、uniswapという分散取引場の取引履歴から、トークンペアの種類をパラメタで指定して集計を実行するクエリ例を示します。
コード1. token_pairをパラメタ化したクエリ例
SELECT token_pair, COUNT(1) AS cnt, SUM(amount_usd) AS total_amount_usd
FROM uniswap_v3_ethereum.trades
WHERE block_time BETWEEN
timestamp '2023-01-01 00:00:00' AND timestamp '2023-01-31 23:59:59'
AND token_pair = '{{token_pair}}'
GROUP BY token_pair
LIMIT 100パラメタ化した箇所のデータは、図1に示すような設定画面で、データ型を指定したり、選択肢を設定したり、他のクエリの出力結果をパラメタとして設定したり、といったカスタマイズが可能です。パラメタ化機能をうまく活用することで、ひとつの汎用的なクエリを用いて、さまざまな切り口からのデータ分析をおこなうこともできます。
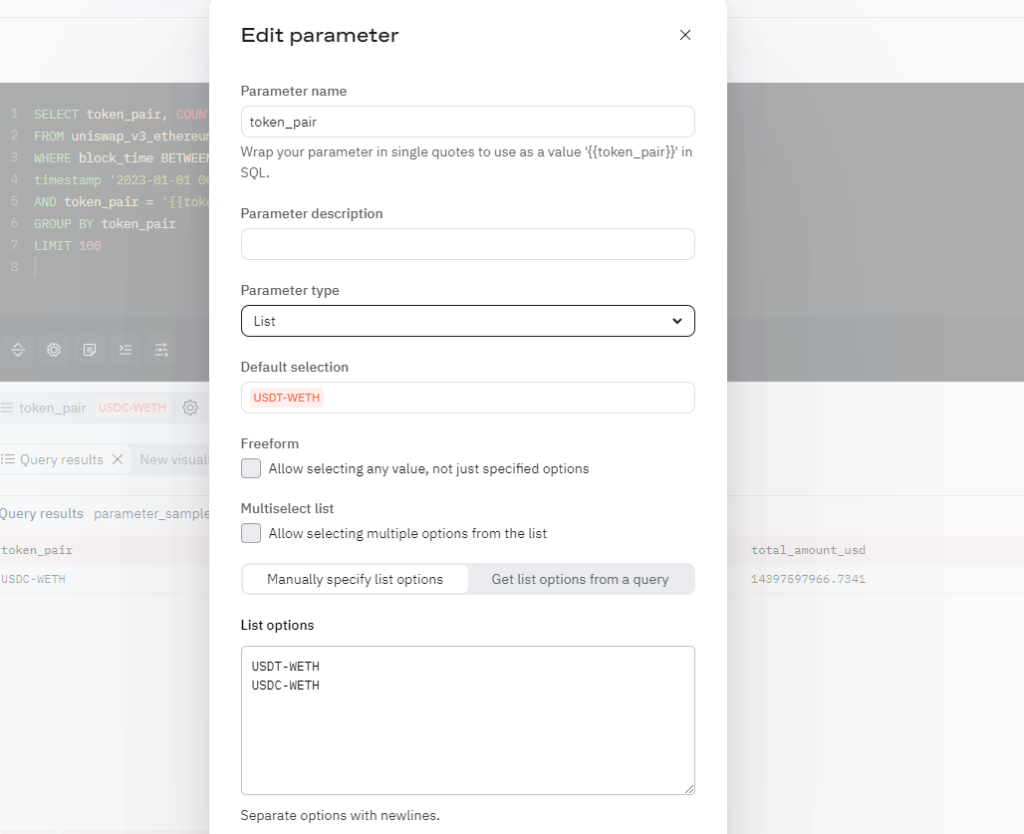
Query Views
過去の記事でも解説した通り、関係演算の閉包性により、SQLクエリの出力結果は別のSQLクエリの入力(FROM句に指定するテーブル)になることができます。それは、WITH句を用いてひとつのクエリ内で名前付けしたテーブルを再利用するだけでなく、異なるクエリ間でも再利用が可能です。
SQL自体の機能にも、「CREATE VIEW」などの構文を用いて、クエリ結果をテーブルとして扱うことができるビューを定義する機能があります。Duneの場合は、クエリエディタで作成し保存したクエリには自動的にIDが振られるため、そのIDを用いてさらに簡単にクエリ結果の参照ができます。
例えば、https://dune.com/queries/3238025 というURLでアクセスできるクエリの結果をSQLで利用するには、URLに含まれる queries/ 以下のクエリIDを用いて、「query_3238025」といったテーブル名で参照するだけです。
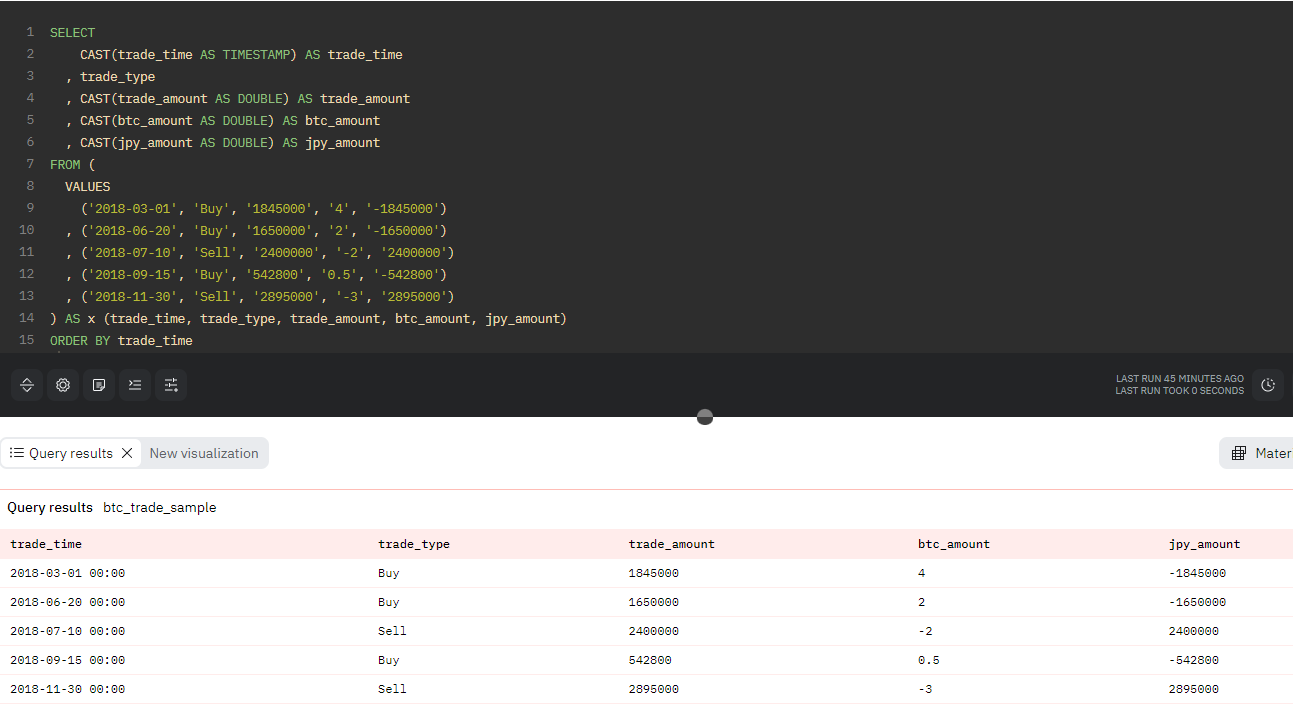
コード2. クエリID: 3238025のビューを参照するクエリ例
SELECT * FROM query_3238025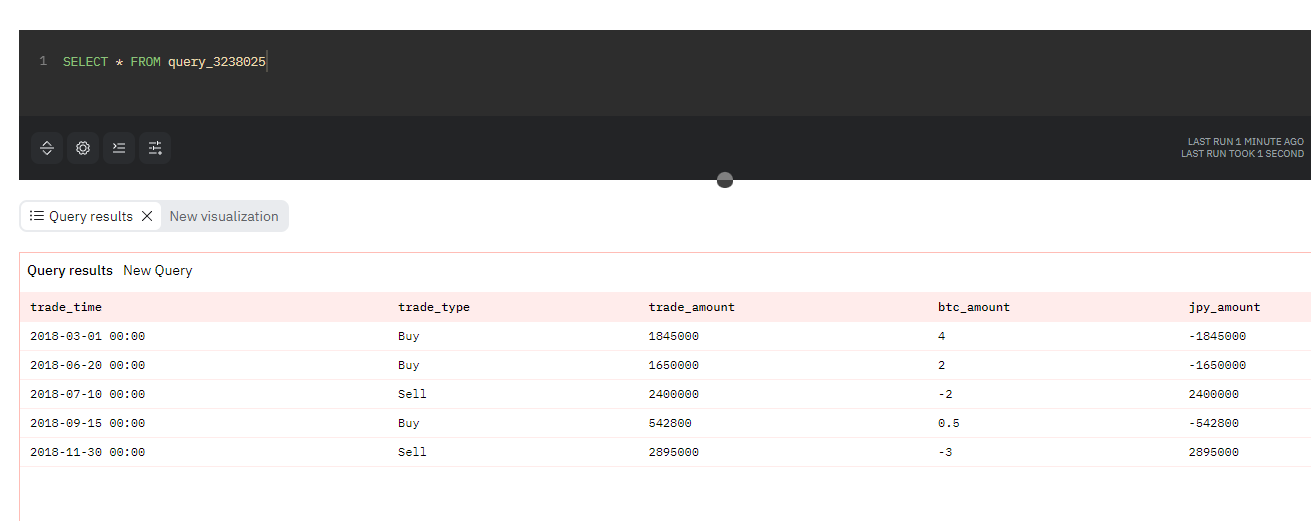
自身が作成したクエリだけでなく、他のユーザーが作成し公開しているクエリも簡単に参照できるので、オンラインコミュニティ全体で共創的なダッシュボード開発が実現できることも、Duneのサービスの魅力です。
分析のための高度なSQL
最後に、Window関数やCASEほど頻出ではないものの、SQLの表現力を拡大させる高度な構文として、ROLLUP(超集合)やWITH RECURSIVE(再帰クエリ)の使い方をご紹介します。
ROLLUP
ダッシュボードやレポートを作成する際、カテゴリごとの集計と、それらを合算した小計、全体の合計などを一度に表示したい場合があります。SQLの場合、同じカラムを持ったテーブル同士をUNIONまたはUNION ALL句で連結することで、一つのテーブルにまとめることができるため、UNION句を用いて小計・合計を含むレポートを作成することができます。
コード3. UNION ALL句を用いて、Ethereum Traceデータの種類ごとの件数と合計を同時に取得するクエリ
WITH target_traces AS (
SELECT *
FROM ethereum.traces
WHERE block_time BETWEEN
timestamp '2023-01-01 00:00:00' AND timestamp '2023-01-01 23:59:59'
)
SELECT 'ALL' AS type, count(1) AS cnt
FROM target_traces
UNION ALL
SELECT type, count(1) as cnt
FROM target_traces
GROUP BY type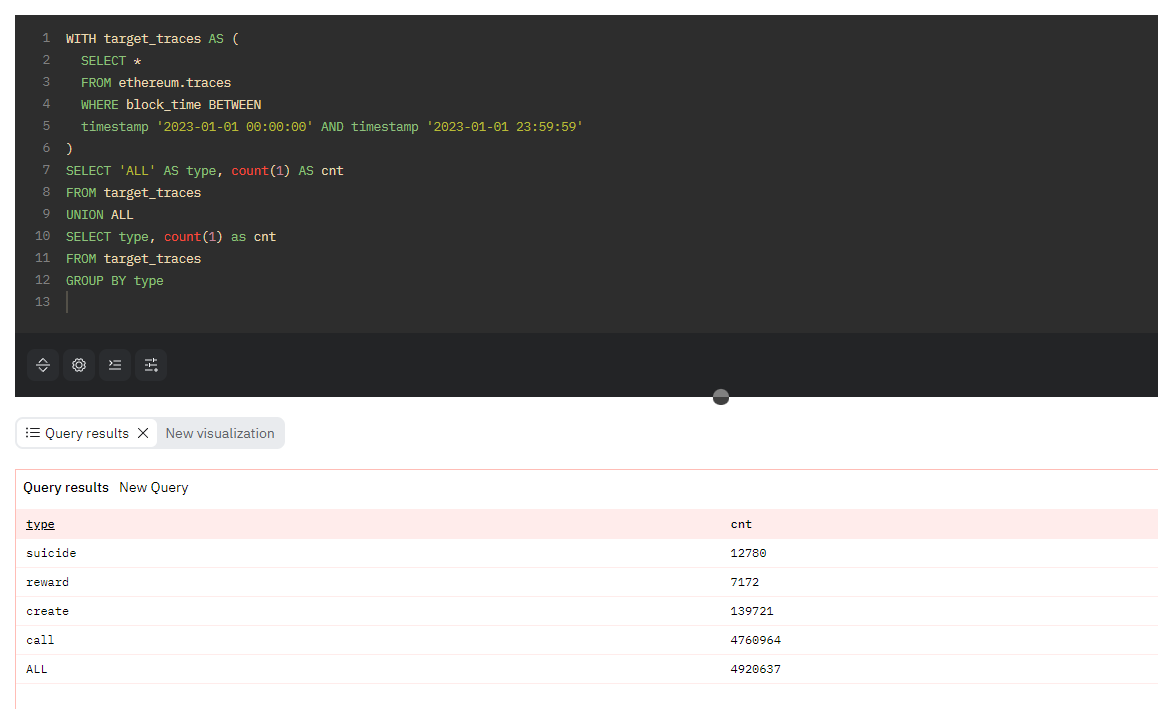
しかし、同じテーブルに対して複数のSELECT文を実行し、UNIONで連結するのは、実行コストが高く、記述も冗長になりがちです。そこで、GROUP BY句にROLLUP句を指定することで、全体の合計と小計を同時に計算することができます。
コード4. コード3と同様の内容をROLLUP句で実現したクエリ
SELECT type, count(1) AS cnt
FROM ethereum.traces
WHERE block_time BETWEEN
timestamp '2023-01-01 00:00:00' AND timestamp '2023-01-01 23:59:59'
GROUP BY ROLLUP(type)
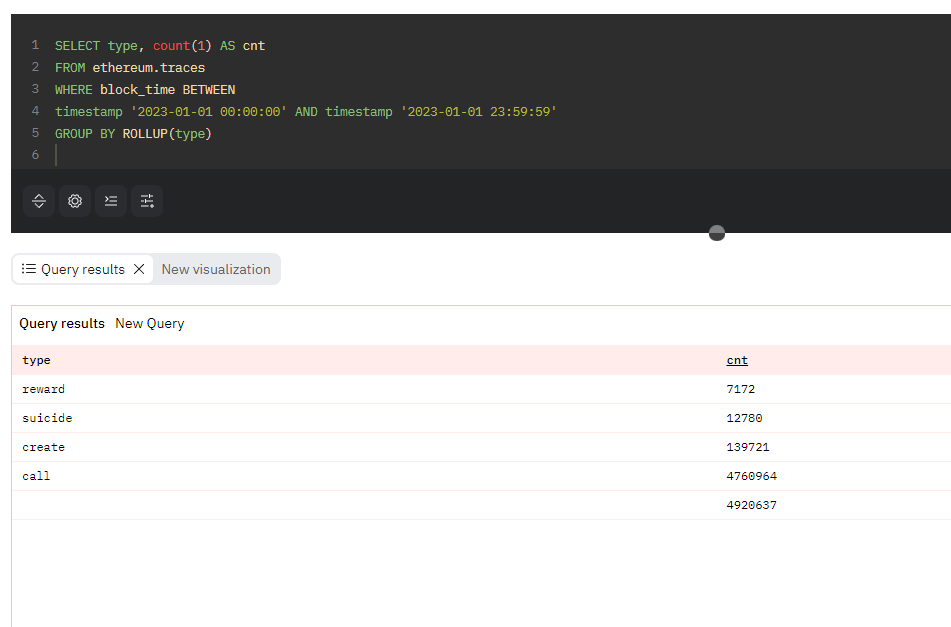
また、ROLLUP句には複数のカラムを指定することもできます。ROLLUP句に複数のカラムを指定した場合、指定した順に応じて小計のグループが細分化されます。例えば、コード5に示すとおり、ROLLUPにtypeとsuccessという2つのカラムを指定した場合、まず冒頭に指定したtypeをもとに小計と合計が計算され、さらにsuccessの中身に応じて細分化された小計が計算されます。2つ目に指定したsuccessのみに応じて細分化された小計(この場合はsuccess=trueのレコード全体とsuccess=falseのレコード全体の小計)は計算されないことに注意してください。
コード5. ROLLUPに複数カラムを指定するクエリ例
SELECT type, success, count(1) AS cnt
FROM ethereum.traces
WHERE block_time BETWEEN
timestamp '2023-01-01 00:00:00' AND timestamp '2023-01-01 23:59:59'
GROUP BY ROLLUP(type, success)
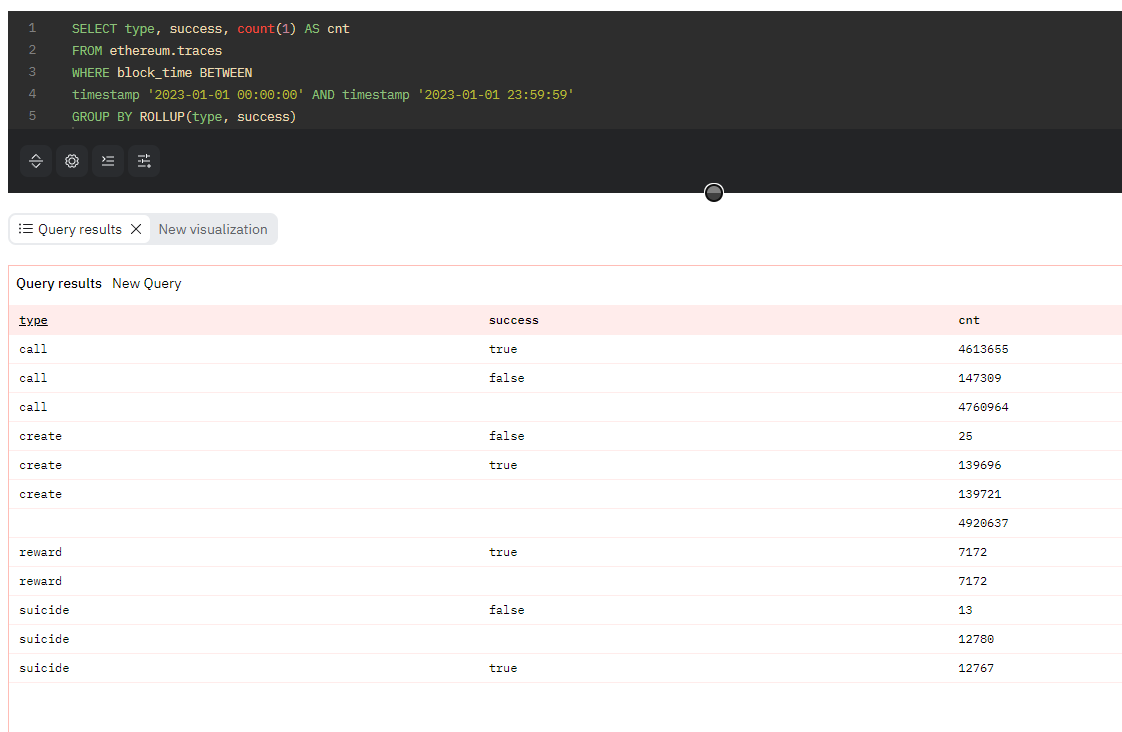
もし、指定したカラムのすべての組み合わせに対する小計を計算したい場合は、ROLLUPではなくCUBE句が利用できます。コード6に示したCUBE句によるクエリ例では、図7に示すとおり、2番目に指定したsuccessカラムだけに基づく小計も計算されています。
コード6. コード5のROLLUPをCUBEに書き換えたクエリ例
SELECT type, success, count(1) AS cnt
FROM ethereum.traces
WHERE block_time BETWEEN
timestamp '2023-01-01 00:00:00' AND timestamp '2023-01-01 23:59:59'
GROUP BY CUBE(type, success)
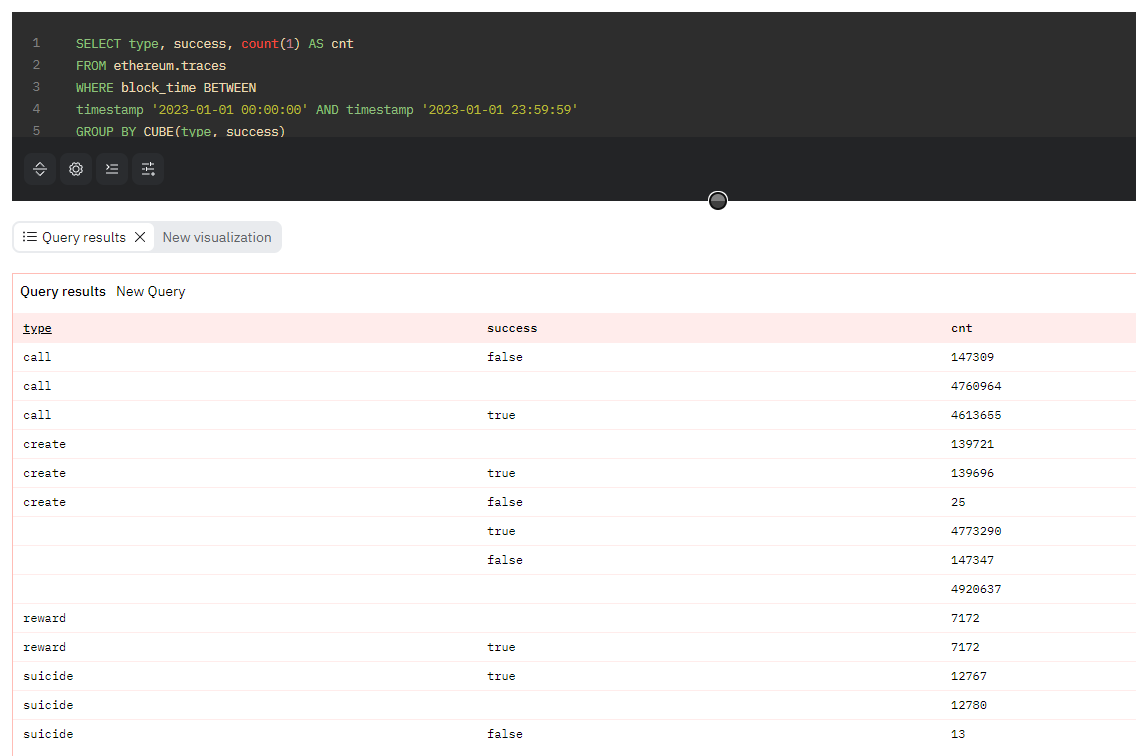
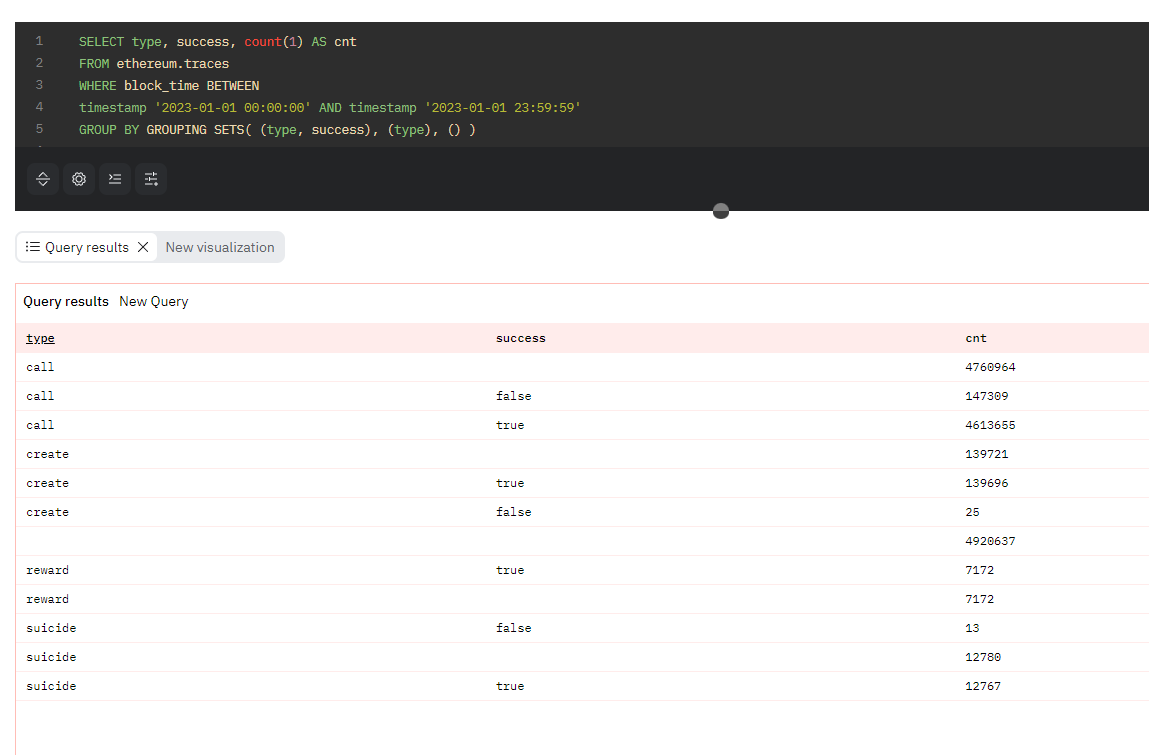
よりカスタマイズされた条件に基づく小計を計算したい場合、GROUPING SETS句を用いることもできます。GROUPING SETS句には、GROUP BYの対象としたいカラムの組み合わせを列挙して指定することができます。「ROLLUP(c1, c2)」という記述は「GROUPING SETS( (c1, c2), (c1), () )」に等しく、「CUBE(c1, c2)」という記述は「GROUPING SETS( (c1, c2), (c1), (c2), () )」に等しくなります。
コード7. コード5のROLLUPをGROUPING SETSで書き換えたクエリ例
SELECT type, success, count(1) AS cnt
FROM ethereum.traces
WHERE block_time BETWEEN
timestamp '2023-01-01 00:00:00' AND timestamp '2023-01-01 23:59:59'
GROUP BY GROUPING SETS( (type, success), (type), () )
WITH RECURSIVE
SQLには、手続き型プログラミング言語のfor文のような繰り返し処理のための構文がないため、逐次処理が苦手と思われがちです。しかし、WITH句のなかで自分自身のテーブルを参照できるWITH RECURSIVE(再帰クエリ)を用いると、無限ループを含む繰り返し処理をSQLで実行することも可能です。
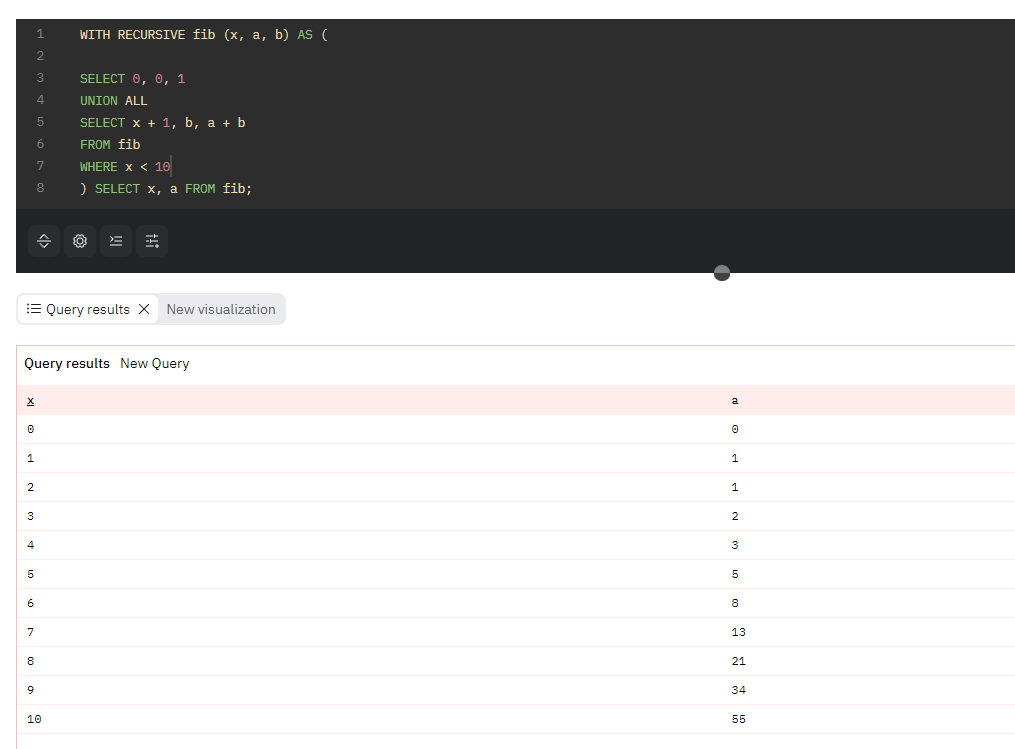
コード8に、WITH RECURSIVEを用いてフィボナッチ数列を計算するクエリ例を示します。WITH RECURSIVEの基本構文は、UNION ALL句を用いて2つのSELECT文を結合し、1つ目のSELECT文では繰り返しの起点となるレコードを指定し、2つ目のSELECT文で繰り返し中の計算処理と終了条件を指定します。
コード8. WITH RECURSIVEを用いてフィボナッチ数列を計算するクエリ例
WITH RECURSIVE fib (x, a, b) AS (
SELECT 0, 0, 1
UNION ALL
SELECT x + 1, b, a + b
FROM fib
WHERE x < 10
) SELECT x, a FROM fib;
WITH RECURSIVEを用いた実用的なクエリ例として、暗号資産の取得価額を移動平均法によって計算するクエリをコード9に示します。暗号資産の取得価額の計算方法については、国税庁による「暗号資産に関する税務上の取扱いについて(FAQ)」(pp.15-16)の事例を参照します。
コード9. WITH RECURSIVEを用いて、移動平均法による暗号資産の取得価額を計算するクエリ
WITH RECURSIVE
t (id, btc_balance, trade_time, trade_type, trade_amount, btc_amount, jpy_amount) AS (
SELECT
ROW_NUMBER() OVER(ORDER BY trade_time) AS id
, SUM(btc_amount) OVER(ORDER BY trade_time) AS btc_balance
, *
FROM query_3238025
)
, moving (id, trade_time, trade_type, btc_amount, jpy_amount, btc_balance, btc_moving_avg_price) AS (
(SELECT id, trade_time, trade_type, btc_amount, jpy_amount, btc_balance, 1.0 * abs(jpy_amount) / btc_amount AS btc_moving_avg_price FROM t WHERE id = 1)
UNION ALL
(SELECT t.id, t.trade_time, t.trade_type, t.btc_amount, t.jpy_amount, t.btc_balance,
CASE
WHEN t.trade_type = 'Sell' THEN moving.btc_moving_avg_price
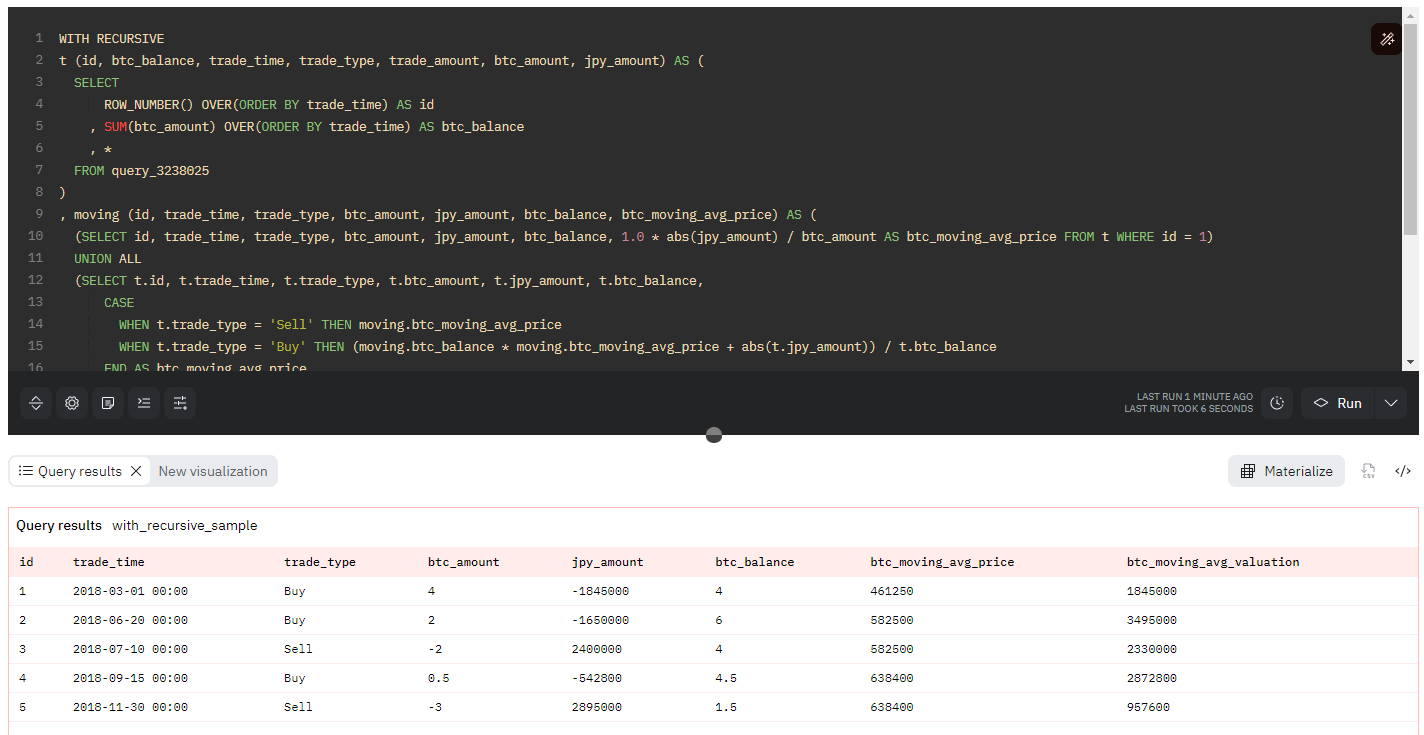
ここでのサンプルデータは、下記のような内訳でビットコインの購入と売却をおこなった場合を想定します。このサンプルデータは、図2に示したクエリ(https://dune.com/queries/3238025)から参照できます。
| 3月1日 | 4 BTCを 1,845,000円で購入 | 保有数量 4 BTC |
| 6月20日 | 2 BTCを 1,650,000円で購入 | 保有数量 6 BTC |
| 7月10日 | 2 BTCを 2,400,000円で売却 | 保有数量 4 BTC |
| 9月15日 | 0.5 BTCを 542,800円で購入 | 保有数量 4.5 BTC |
| 11月30日 | 3 BTCを 2,895,000円で売却 | 保有数量 1.5 BTC |
コード9のクエリを細分化して解説します。まず、サンプルデータには取引時点での保有BTCの残高を示すカラムがないので、Window関数を用いて累計のBTC残高を計算します。また、取扱を簡単にするため、取引履歴順に連番のIDを付与します(コード10)。
コード10. BTC取引履歴の前処理部分
SELECT
ROW_NUMBER() OVER(ORDER BY trade_time) AS id
, SUM(btc_amount) OVER(ORDER BY trade_time) AS btc_balance
, *
FROM query_3238025
移動平均法を用いた暗号資産の平均単価は、「取引時点で保有する暗号資産の簿価の総額 / 取引時点で保有する暗号資産の数量」で計算されます。
例えば、3月1日時点でのビットコインの平均単価は、ビットコインの簿価の総額が1,845,000円であり、保有するビットコインの数量が 4 BTCなので、1 BTCあたりの平均単価は 1,845,000 / 4 = 461,250円となります。コード11に示す再帰クエリのなかでは、UNION ALL句の前側のSELECT文で、この計算をおこなっています。
続いて、6月20日時点の場合を計算します。この時点でのビットコインの簿価の総額は、過去に保有しているビットコインの簿価+新規購入額となります。すなわち、上記で計算した平均単価461,250円 × 保有ビットコイン 4 BTC + 新規購入額 1,650,000円 = 3,495,000円です。また、この時点で保有するビットコインの数量は 6 BTCなので、1 BTCあたりの平均単価は 3,495,000 / 6 = 582,500円となります。この計算は、コード11においては「WHEN t.trade_type = ‘Buy’ THEN~」に続く箇所で計算しています。
7月10日の取引は、保有しているビットコインの売却なので、平均単価には影響せず、1 BTCあたりの平均単価は6月20日時点と同じ582,500円となります。コード11においては「WHEN t.trade_type = ‘Sell’ THEN」に続く箇所が、該当する計算箇所です。
9月15日の取引では、新たに 542,800円分のビットコインを購入し、合計4.5 BTCを保有していることになるので、平均単価は (582,500円 × 4 BTC + 542,580円)/ 4.5 BTC = 638,400円となります。
11月30日の取引では、ビットコインの売却のため平均単価には影響せず、同じく638,400円が1 BTCあたりの平均単価です。
コード11. 移動平均法を計算する再帰クエリの中核部分
(SELECT id, trade_time, trade_type, btc_amount, jpy_amount, btc_balance, 1.0 * abs(jpy_amount) / btc_amount AS btc_moving_avg_price FROM t WHERE id = 1)
UNION ALL
(SELECT t.id, t.trade_time, t.trade_type, t.btc_amount, t.jpy_amount, t.btc_balance,
CASE
WHEN t.trade_type = 'Sell' THEN moving.btc_moving_avg_price
WHEN t.trade_type = 'Buy' THEN (moving.btc_balance * moving.btc_moving_avg_price + abs(t.jpy_amount)) / t.btc_balance
END AS btc_moving_avg_price
FROM moving
JOIN t ON moving.id = (t.id - 1)
)
このように、前の計算結果を引き継いで次の計算をおこなう必要がある場合、WITH RECURSIVEによる再帰クエリが力を発揮します。上記の説明文で計算したビットコインの平均単価と、図10に示す計算結果が一致していることを確認してみてください。
まとめ
全8回の連載を通じて、ブロックチェーンの基本的な仕組みの解説と、代表的なブロックチェーンであるビットコインとイーサリアムのデータ構造の解説、および、SQLを用いたオンチェーンデータ分析の演習をおこないました。これからSQLを用いてデータ分析の技術を磨きたい人にとって、ブロックチェーンのオンチェーンデータは手軽にアクセスできるリアルなデータソースとしておすすめです。また、ブロックチェーンに関する知識を深めたい人にとっても、自分でSQLを記述しながら実データを分析するプロセスは非常に有益です。本連載を通じて、読者の皆様がSQLやブロックチェーン技術の魅力を発見する一助となれば幸いです。
連載一覧
【第1回】ブロックチェーンとは
【第2回】ビットコインの仕組み
【第3回】イーサリアムの仕組み
【第4回】ビッグデータ分析のためのSQL基礎
【第5回】Ethereumデータ分析演習1
【第6回】Ethereumデータ分析演習2
【第7回】Ethereumデータ分析演習3
【第8回】Ethereumデータ分析演習4
【Sqripts編集部より】
加嵜長門さんの連載記事『ブロックチェーンの仕組みとオンチェーンデータ分析』はいかがでしたでしょうか。
読者のみなさまからの感想や今後の連載のリクエストをぜひお寄せください!
Sqriptsお問い合わせ、または公式XアカウントのDMでも受け付けています。
#Ethereum #オンチェーン分析




