



第五回の連載では湯本が確立したテスト手法であるIDAU法のテストプロセスをツール実装し検証した研究について説明しました。第六回では、前回記事の中で述べた仮説の一つである、IDAU法をソースコードレベルのテストに適用するために独自の拡張を加えた、Code Based IDAU法(CB-IDAU)の研究について説明したいと思います。
IDAU法の課題とCB-IDAU法の仮説のおさらい
前回の第五回の記事において、湯本が確立したIDAU法をツール実装し自動化する際に確認された課題と、その解決案の一つとして導き出したCB-IDAU法の仮説について、再度、説明します。
IDAU法が対象としていたテスト工程は、結合テストやシステムテストなどのテストの後工程を対象として開発されたテスト手法であり、テストのためのインプット情報は、フロー図や機能設計書などの自然言語で記載されたドキュメントを、テスターが読み込むことでテスト項目作成に必要となる、機能とデータの操作情報の組み合わせを特定するものでした。IDAU法は、テスト技法としては、矛盾なく確立した手法ですが、自動化やツール化という観点では、テストのためのインプット情報の収集が人間系での手作業にならざるを得ないため、効率性や正確性の観点で課題がありました。そこで、前回の連載で記載したように、テストのインプット情報を機械的に入手可能な、ソースコードレベルのテストにIDAU法を応用することで、これらの課題を克服しつつ、新しいCB-IDAU法の仮説を提案しました。図1にIDAUとCB-IDAU法のアプローチの違いについて図示します。IDAU法では、システムの機能単位でのデータ操作をテスト観点としているのに対して、CB-IDAU法ではプログラムのコードの依存関係とデータ操作をテスト観点としている違いがあります。
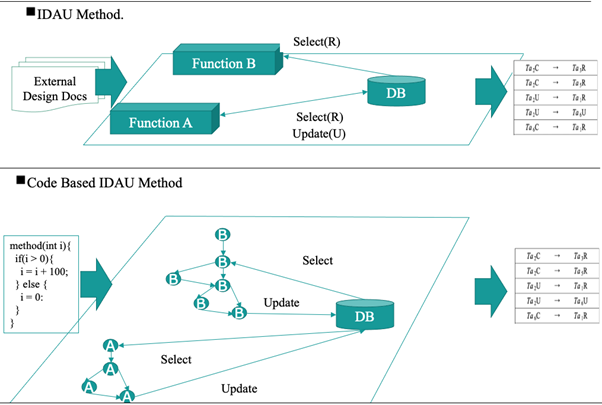
仮説実現のための課題と対策
CB-IDAU法は、ソースコードレベルのテストにIDAU法を適用したものであり、データ操作に関する情報を網羅的に抽出した後、拡張CRUD図に基づいて、テスト項目として抽出する対を特定するプロセスに違いはありませんが、大量のプログラムの呼出関係から、自動的に且つ正確にデータ操作に関する情報を抽出するために、主にテストのためのインプット情報を取得する事前処理のプロセスがIDAU法とは大きく異なっています。何故なら、単にIDAU法をソースコードレベルのテストに応用すると言っても、以下のような課題があり、それらの課題を解決するための手法を取り入れる必要があるためです。
- 課題1. プログラミング言語依存性
ソースコードを構成するプログラム言語はPython, Java, C言語のように様々な種類のプログラミング言語が存在し、データを呼出し操作する記述はそれぞれに異なるため、どのようにしてプログラミング言語の違いを吸収するのか?
- 課題2. CRUD操作とプログラム呼出関係のマッピング
ソースコードにおいてデータを操作するための記述は多様性があり、どのようにして最終的に全てのデータ操作のソースコードを、CRUDの4種類のデータ操作にマッピングするのか?
- 課題3. 大量な呼出関係からのテストケースの抽出方法
膨大な数に登るソースコードの呼出関係を、どのようにして網羅的に解析して、最終的なテストケースの抽出を行うのか?
CB-IDAU法の研究においては、これらの課題の克服のために、以下のような対策を行いました。
- 課題1と課題2の対策:3番地中間言語の採用
ソースコードを3番地コードの中間言語に変換し、プログラミング言語非依存で、解析可能な有限の命令情報に集約することで、これらの課題を克服しました。
現存するプログラミング言語の全ての構文や命令セットに対して、解析可能な機能を実装することは現実的に不可能です。そのため、この問題を解決するための一つの手段として、解析対象となるプログラミング言語を、抽象化された中間言語に変換した後に、具体的なコード解析を行う手法が考えられます。中間言語とはIntermediate Languageと呼ばれており、プログラミング言語のコンパイラが、人間が記述したソースコードからCPUが実行可能なマシン語に変換する前に、コンパイラの変換効率を上げるためにソースコードを最適化する際に用いられます。例えば、Javaではバイトコード、C言語ではオブジェクトコードなどが中間言語として利用されています。そして、これらの中間言語が持つ表現形式のことを、Intermediate Representation (IR)と呼びます。このIRの種類の一つとして、3番地コード Three Address Codeと呼ばれる形式のものがあり、以下のような処理構造のみでプログラムの処理を表現する方式です。全てのプログラミングの処理を論理的な最小構造に分解すると、この3番地コードのIR形式のみで構成されることが知られています。
X = Z 処理 Y
この3番地コードIR形式を採用した、具体的な中間言語の一つにJimpleと呼ばれる中間言語があります。Jimpleではこの処理にあたるオペランドの種類が46個と有限であり、本研究では、これらのオペランドの操作に対してCRUDを定義することで、大量のソースコードの処理に対して自動的にCRUD情報の抽出を実現しました。各オペランドの説明等については、ソフトウェアテストのスコープからは外れてしまう内容のため、ここでは省略します。
- 課題3の対策:グラフ構造モデリングと探索アルゴリズム
ソースコードをCall Graph (CG)及びControl Flow Graph (CFG)として、数学的なノードとエッジの2つから構成されるグラフデータ構造として表現することで、グラフ探索による正確かつ網羅的な解析を可能としました。CB-IDAUの研究では、ソースコードを3番地コードの中間言語であるJimpleに変換し最適化された後に、CGとCFGを生成しています。ソースコードの情報をグラフデータ構造として解析ツール内部で保持することにより、大量のデータ操作に関する情報や依存関係の処理を、CB-IDAU法の実装ツール内部で扱い易くします。この3番地コードIR形式を採用した、具体的な中間言語の一つにJimpleと呼ばれる中間言語があります。本研究では、ソースコードをJimpleに変換して、操作に対してCRUDを定義することで自動的にCRUD情報を抽出するようにしました。実際に研究のサンプルコードとして用いたJavaプログラムをJimpleに変換して生成したCFGの例を図2に示します。
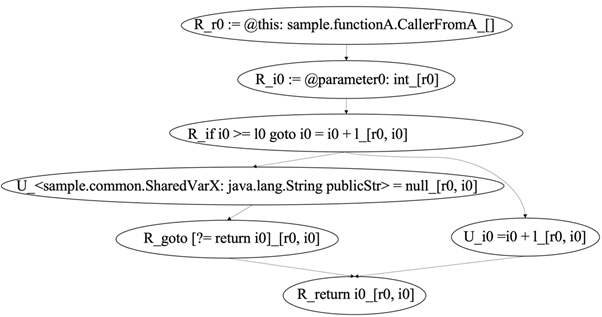
本研究では、JavaのコードからJimpleへの変換、CGとCFGの生成については、オープンソースライブラリのSootを用いました。また、グラフ構造の描画については、代表的なグラフ描画オープンソースである、graphvizとigraphを用いました。
続きを読むにはログインが必要です。
ご利用は無料ですので、ぜひご登録ください。








